Les points essentiels à retenir avant de l’activer
- La solution fonctionne comme une CNAPP: elle réunit posture de sécurité, protection des workloads et lecture DevSecOps dans une seule vue.
- Le socle gratuit inclut la CSPM fondatrice, les recommandations, l’inventaire d’actifs, le score de sécurité et la conformité de base.
- Une période d’essai de 30 jours existe, mais la facturation réelle dépend ensuite des plans activés et du périmètre couvert.
- Le score de sécurité va de 0 à 100 et sert surtout à prioriser les corrections, pas à remplacer une analyse humaine.
- La vraie valeur apparaît quand on relie le cloud, les pipelines DevOps et les machines hybrides au même modèle de risque.
Ce que la plateforme apporte réellement
Je la lis comme une CNAPP, c’est-à-dire une plateforme unifiée qui réunit trois briques: la gestion de la posture de sécurité cloud, la protection des charges de travail et une couche DevSecOps qui relie le code au runtime. En clair, elle ne se contente pas de dire qu’un paramètre est mal réglé; elle vous aide à comprendre où le risque naît, comment il se propage et quelle correction apporte le meilleur gain.
C’est important parce qu’en cloud, le problème le plus fréquent n’est presque jamais un seul incident spectaculaire. On retrouve plutôt un mélange de permissions trop larges, de ressources exposées, de dépendances non corrigées et de politiques mal alignées avec la responsabilité partagée. C’est précisément là que cette approche devient utile: elle transforme une masse de signaux techniques en actions prioritaires. La question suivante est donc simple: sur quels environnements et dans quels flux cette vision fonctionne-t-elle le mieux?
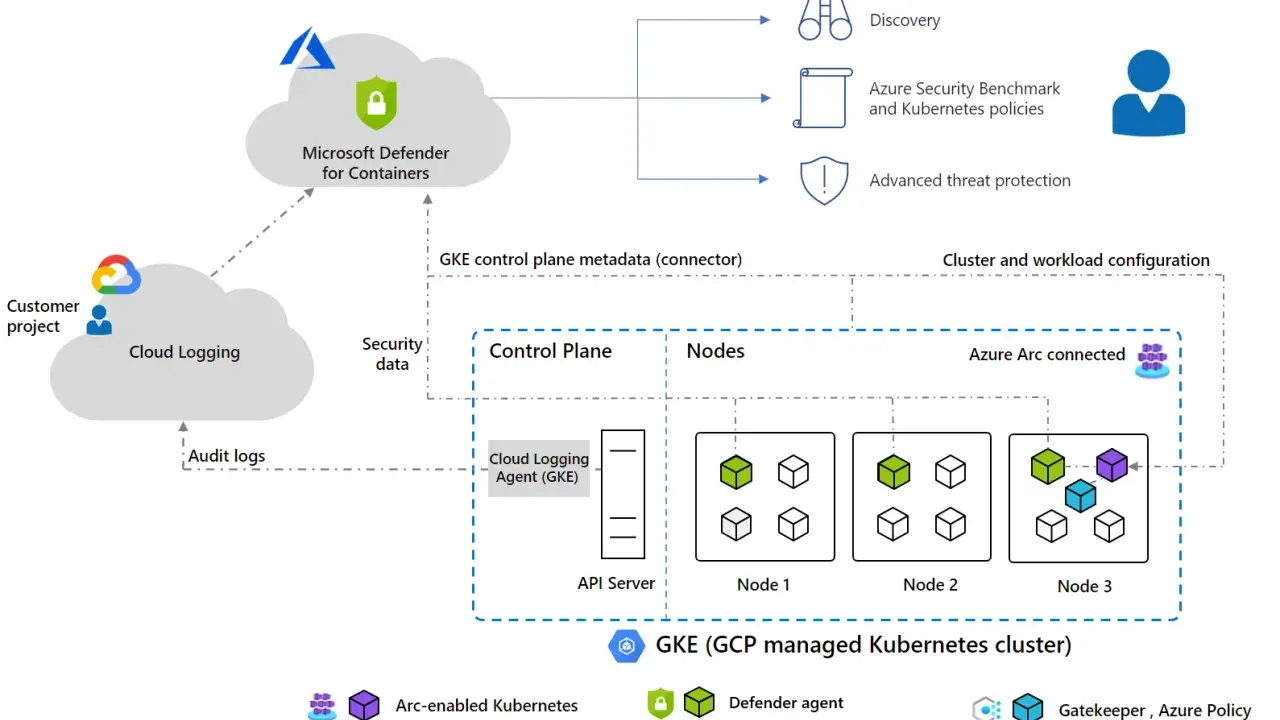
Comment elle couvre Azure, AWS, GCP et les flux DevOps
La force du service, c’est sa vue croisée. Une fois connecté, il peut suivre des abonnements Azure, des comptes AWS, des projets GCP et, selon le périmètre, des environnements DevOps. Je trouve cette approche utile parce qu’elle évite le piège classique du cloisonnement: une posture propre dans un cloud ne signifie rien si le dépôt Git, la chaîne CI/CD ou la machine d’exécution restent mal protégés.
Dans la pratique, la solution expose un inventaire d’actifs, des recommandations, des alertes et une lecture de la conformité. Pour une équipe sécurité, cela permet de relier un même incident à la ressource concernée, à son exposition et à ses remédiations possibles. Pour une équipe système ou cloud, c’est surtout un moyen de ne plus traiter chaque alerte comme un cas isolé.
| Périmètre | Ce que cela apporte | Ce qu’il faut vérifier |
|---|---|---|
| Azure, AWS et GCP | Vue de la posture, recommandations, score de sécurité, conformité et inventaire unifié | Le périmètre réellement connecté, la qualité des tags et la séparation par abonnement ou compte |
| DevOps | Lecture du risque dès le code, liens code-to-cloud, annotations de pull request et priorisation | La maturité de vos pipelines, la discipline de revue et la capacité à corriger avant la mise en production |
| Hybride et non-Azure | Couverture des machines via Azure Arc ou des intégrations adaptées | Le mode d’onboarding des serveurs et le niveau de contrôle que vous voulez conserver sur chaque environnement |
En pratique, cette vision multicloud n’est réellement efficace que si l’on accepte de piloter la sécurité comme un ensemble cohérent, pas comme une succession d’outils. Une fois cette couverture comprise, la vraie question devient celle du déploiement: par quoi commencer sans multiplier le bruit inutile?
Ce qu’il faut activer en premier
Je conseille de commencer petit, mais proprement. Un bon déploiement ne consiste pas à tout ouvrir d’un coup; il consiste à obtenir un premier niveau de visibilité, puis à étendre la couverture là où le risque est le plus élevé. C’est souvent là que les projets se gagnent ou se perdent.
- Activez d’abord le socle gratuit sur le périmètre pilote le plus représentatif.
- Vérifiez l’inventaire d’actifs et la première vague de recommandations, puis éliminez les faux positifs évidents.
- Priorisez les workloads les plus exposés: serveurs, bases de données, stockage et conteneurs sont souvent les premiers à justifier un durcissement.
- Reliez les environnements AWS, GCP ou on-prem si vous avez un réel besoin multicloud ou hybride, sinon gardez le scope simple au départ.
- Préparez la remédiation avant d’augmenter la couverture: propriétaire, délai de correction, validation et suivi.
J’insiste sur ce point parce qu’un outil de posture de sécurité devient vite contre-productif s’il n’est pas relié à une chaîne de correction claire. Si vous savez déjà quoi activer en premier, il reste à distinguer ce qui est couvert gratuitement de ce qui fait vraiment monter la facture.
Gratuit, payant, et ce qui change vraiment
La première bonne nouvelle, c’est qu’un socle gratuit existe dès l’activation initiale: CSPM fondamental, recommandations, inventaire d’actifs, score et conformité de base. Une période d’essai de 30 jours est aussi disponible sur la première activation, mais je la considère comme un test fonctionnel, pas comme une stratégie d’exploitation à long terme. Ensuite, la facture dépend surtout des plans activés et du nombre de ressources protégées.
| Bloc | Ce que cela couvre | Quand le choisir | Point d’attention |
|---|---|---|---|
| Socle CSPM fondamental | Recommandations de base, score, inventaire, conformité de référence | Pour obtenir une visibilité initiale sans surcoût | Ce n’est pas suffisant pour une protection runtime avancée |
| Defender CSPM | Priorisation avancée, analyse des chemins d’attaque, posture assistée par IA et meilleure lecture du risque | Quand vous voulez passer d’un simple inventaire à une vraie hiérarchisation des menaces | Le coût dépend du périmètre réellement couvert |
| Plans workload spécialisés | Protection des serveurs, conteneurs, bases de données, stockage, App Service, Key Vault, Resource Manager, APIs et DevOps | Quand vous devez protéger des services en production et pas seulement leur posture | Chaque plan doit être scoping correctement pour éviter une dérive budgétaire |
Lire aussi : Sécurité informatique - Comment bâtir une défense robuste et efficace
Le cas des serveurs
Le plan serveurs mérite un regard à part, parce que c’est souvent le premier poste de dépense concret. Le Plan 1 s’appuie surtout sur l’intégration avec la détection et réponse de Microsoft pour fournir une protection de type EDR, tandis que le Plan 2 ajoute des capacités plus larges: scan agentless, évaluation des vulnérabilités, recherche de malwares, détection de secrets et fonctions de conformité plus avancées.
- Plan 1: utile si vous voulez surtout renforcer la détection et la réponse sur des serveurs déjà bien gérés.
- Plan 2: préférable si vous cherchez une couverture plus complète de la posture et des risques techniques.
- Certains scénarios de Plan 2 peuvent aussi nécessiter un espace de travail Log Analytics, notamment pour certaines formes d’ingestion ou de surveillance.
Autrement dit, le bon arbitrage n’est pas seulement budgétaire: il dépend aussi du niveau de maturité de vos équipes et de la profondeur de protection attendue. Quand le coût est clair, il faut encore savoir lire correctement le score et les recommandations pour éviter les mauvaises interprétations.
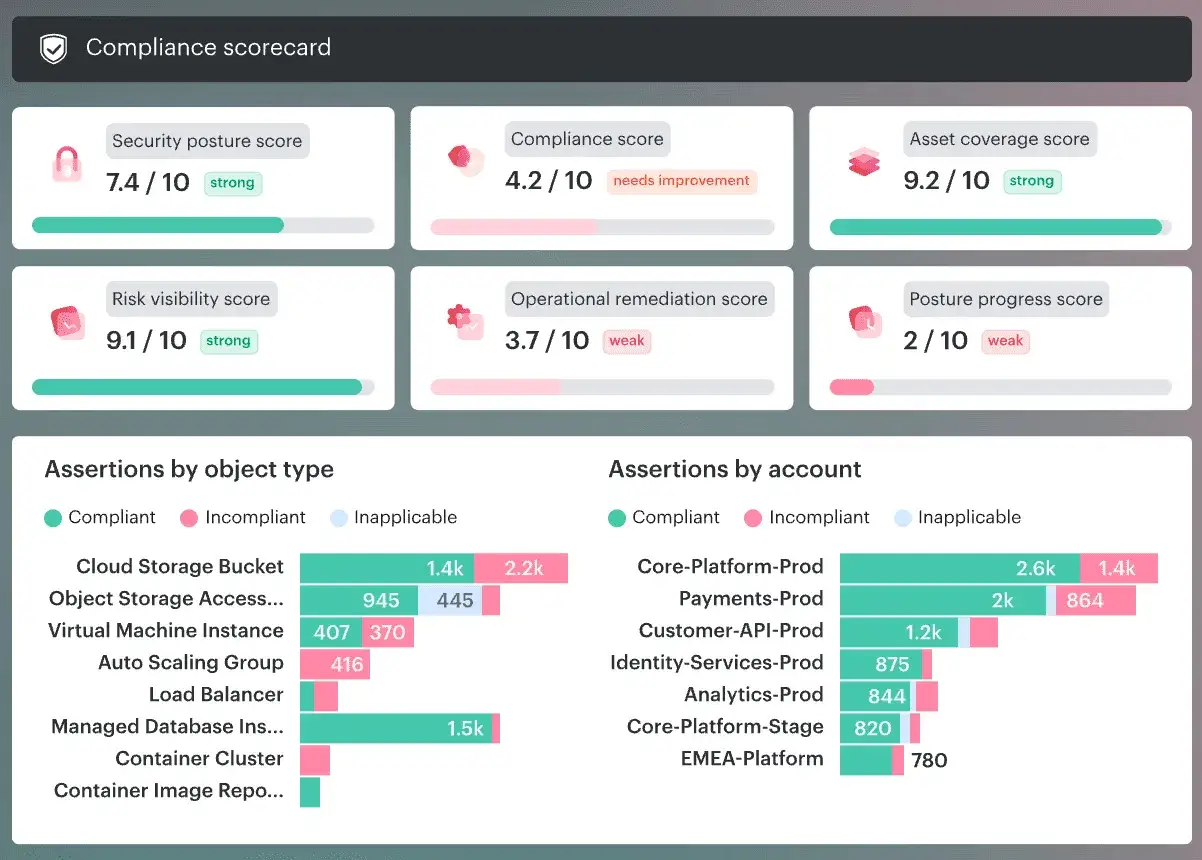
Lire le score, les recommandations et la conformité sans se tromper
Le score de sécurité cloud va de 0 à 100. Je l’utilise comme un thermomètre de progression, pas comme une note de conformité finale. Le référentiel Microsoft Cloud Security Benchmark est appliqué par défaut, et les recommandations qui en découlent servent à faire remonter les points de friction les plus rentables à corriger en premier.
- Le score agrège des signaux, il ne remplace pas une revue d’architecture ni une analyse des identités.
- Les recommandations marquées comme préversion ne comptent pas encore dans le calcul, même si elles méritent souvent d’être corrigées rapidement.
- Le volet conformité permet de suivre les écarts par standard, ce qui est précieux pour préparer un audit ou une revue interne.
Je trouve cette logique saine, à condition de ne pas confondre visibilité et remédiation automatique. Le tableau vous dit où agir d’abord, mais il ne fait pas le travail à votre place. C’est justement ce qu’il faut garder en tête avant de regarder les erreurs qui coûtent le plus cher.
Les erreurs qui coûtent cher et les limites à connaître
Les déploiements ratés suivent souvent le même scénario: on active trop vite, on scope mal, puis on finit avec un centre de supervision saturé d’alertes. J’ai vu plusieurs équipes gagner du temps simplement en évitant ces quatre pièges de base.
| Erreur fréquente | Conséquence | Bon réflexe |
|---|---|---|
| Tout activer sur tout le périmètre | Bruit, coûts plus élevés et difficulté à prioriser | Démarrer par un pilote et étendre ensuite par criticité |
| Confondre score et sécurité réelle | Fausse impression de maîtrise | Croiser le score avec l’exposition, les identités et les journaux d’activité |
| Oublier les machines hybrides ou non-Azure | Trous de couverture | Prévoir Azure Arc ou le mécanisme d’onboarding adapté dès le départ |
| Ne pas préparer la remédiation | Accumulation d’alertes sans traitement | Assigner un propriétaire et un délai pour chaque catégorie de recommandation |
Le cadrage que je recommande pour une adoption utile
Si je devais résumer la bonne méthode, je dirais ceci: commencez par la visibilité, puis par la priorisation, et seulement ensuite par l’extension de la protection. C’est la séquence qui évite les déploiements trop ambitieux et les tableaux de bord qui impressionnent sans réellement réduire le risque.
- Établissez une base avec le socle gratuit et un score de départ lisible.
- Activez un ou deux plans workload sur les ressources les plus critiques, pas sur tout le parc.
- Reliez chaque alerte à un propriétaire métier ou technique, sinon la remédiation s’enlise.
- Recalculez votre priorité à intervalles réguliers, surtout après une mise en production ou un changement d’architecture.