
Les priorités à retenir avant de choisir des outils
- La première cible d’un attaquant reste souvent l’identité: mots de passe faibles, comptes partagés et absence de double authentification.
- Les correctifs, la protection des postes et les sauvegardes isolées apportent plus de sécurité que beaucoup d’achats spectaculaires.
- Une défense efficace combine prévention, détection et reprise, pas seulement un antivirus.
- La règle 3-2-1 pour les sauvegardes et des tests de restauration réguliers restent des standards très solides.
- Les outils ne valent que s’ils sont configurés, surveillés et testés dans de vrais scénarios d’incident.
Ce que recouvre une protection efficace des systèmes et des réseaux
Pour moi, la vraie question n’est pas « quel outil acheter ? », mais « qu’est-ce qu’on doit empêcher, détecter ou réparer ? ». Une stratégie sérieuse protège quatre choses en même temps: les identités, les terminaux, les flux réseau et les données. Si l’un de ces blocs est négligé, l’attaquant ne force pas forcément la porte principale; il passe souvent par un compte oublié, un poste non corrigé ou une sauvegarde trop exposée.
- Les identités : comptes utilisateurs, administrateurs, accès cloud, boîtes mail et droits applicatifs.
- Les terminaux : PC, portables, mobiles, serveurs et machines virtuelles.
- Le réseau : pare-feu, segmentation, accès distants et filtrage des flux.
- Les données : fichiers métier, bases clients, sauvegardes, clés de chiffrement et journaux.
Cette lecture par actifs est utile parce qu’elle évite les achats réflexes. On ne sécurise pas un système d’information en bloc; on sécurise des points précis, avec des moyens proportionnés à leur criticité. C’est aussi ce qui permet de passer d’une posture défensive vague à un dispositif réellement pilotable, ce qui nous amène aux menaces les plus fréquentes.
Les menaces à traiter en premier
Je commence toujours par les attaques qui fonctionnent parce qu’elles sont simples, pas forcément parce qu’elles sont très techniques. Le hameçonnage, le vol d’identifiants, les rançongiciels et l’exploitation de failles non corrigées restent les scénarios les plus rentables pour un attaquant. Je n’oublie pas non plus le risque fournisseur: une application SaaS ou un prestataire compromis peut devenir la porte d’entrée d’une intrusion.| Menace | Ce qui se passe | Premier réflexe utile |
|---|---|---|
| Hameçonnage | Un message pousse un collaborateur à cliquer, saisir un mot de passe ou valider une action frauduleuse. | Double authentification, sensibilisation ciblée et filtrage de messagerie. |
| Identifiants volés | Un compte est réutilisé sur un service externe ou récupéré après une fuite. | Mot de passe unique, gestionnaire de mots de passe, MFA et surveillance des connexions anormales. |
| Rançongiciel | Les données sont chiffrées, parfois après exfiltration, puis la victime est mise sous pression. | Sauvegardes isolées, segmentation réseau, moindre privilège et plan de réponse. |
| Faille non corrigée | Un système exposé reste vulnérable parce qu’un correctif a été repoussé. | Politique de mise à jour priorisée et inventaire des actifs. |
Le point commun de ces attaques est banal: elles exploitent moins la haute technologie que le relâchement opérationnel. Tant que l’on n’a pas réduit ces quatre risques, le reste du dispositif reste fragile, d’où l’intérêt d’une défense en profondeur.
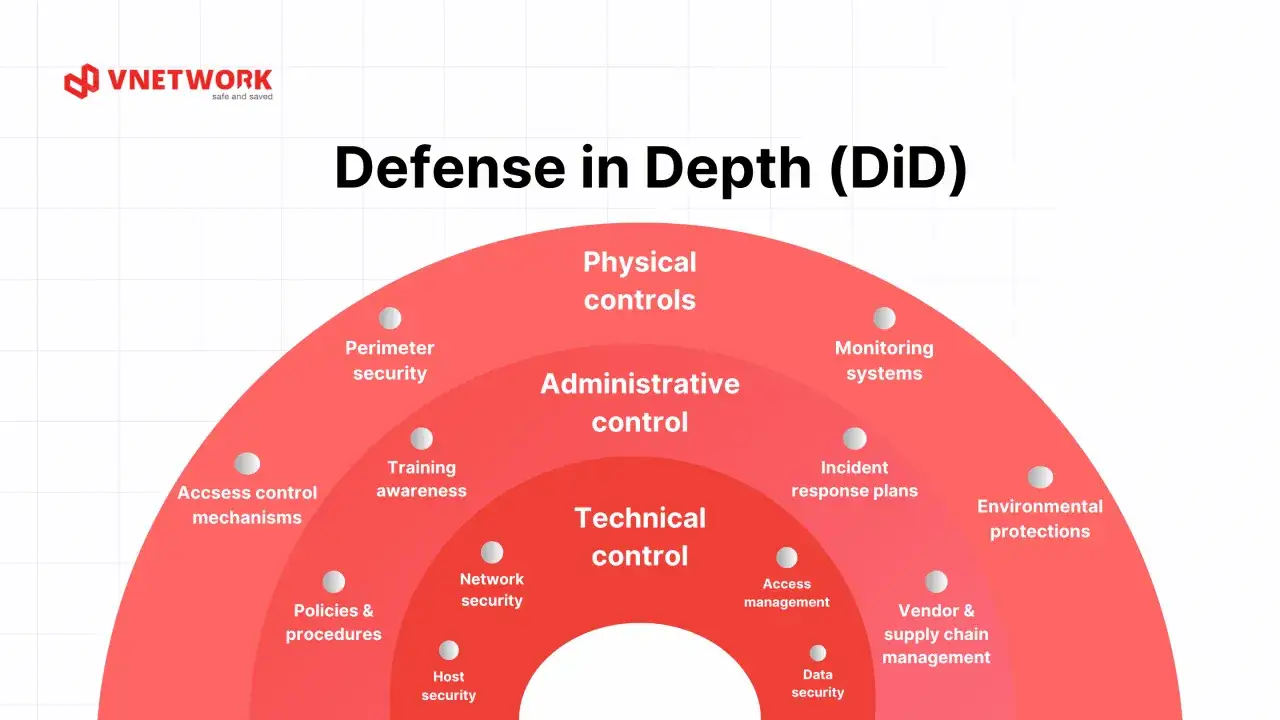
Les couches de protection qui font la différence
J’aime raisonner en couches, parce qu’aucun contrôle n’est parfait. Un pare-feu arrête une partie des flux, mais il ne remplace ni la MFA ni les sauvegardes. Un antivirus détecte une partie des malwares, mais il ne voit pas forcément un compte compromis qui agit “normalement”. La MFA, ou authentification multifacteur, ajoute un second facteur de vérification; l’EDR surveille le comportement des postes; le SIEM centralise les journaux pour corréler les alertes; le ZTNA applique une logique d’accès minimale au lieu d’ouvrir un réseau entier.| Couche | Technologies utiles | Ce qu’elles apportent | Limite |
|---|---|---|---|
| Identité | MFA, SSO, gestionnaire de mots de passe, PAM | Réduit fortement l’usage abusif de comptes et limite les droits admin. | Demande une bonne gouvernance des comptes et des exceptions. |
| Postes et serveurs | EDR, antivirus de nouvelle génération, chiffrement du disque, MDM, patch management | Bloque une partie des malwares, surveille les comportements et accélère les corrections. | Ne compense pas un poste mal configuré ou non mis à jour. |
| Réseau | Pare-feu, segmentation, VPN ou ZTNA, filtrage DNS | Limite la propagation latérale et réduit les accès inutiles. | Un réseau plat reste risqué, même avec un bon pare-feu. |
| Données | Chiffrement, DLP, sauvegarde 3-2-1, immutabilité | Protège les fichiers sensibles et rend la reprise possible après incident. | Une sauvegarde non testée n’est qu’une promesse. |
| Supervision | SIEM, journaux centralisés, alerting, SOAR | Permet de repérer des signaux faibles et d’accélérer la réponse. | Génère du bruit si les cas d’usage ne sont pas bien définis. |
Je retiens surtout une chose: il vaut mieux six contrôles bien tenus que quinze outils décoratifs. Les recommandations de l’ANSSI vont d’ailleurs dans le même sens sur la sauvegarde: elle doit être isolée, testée et réellement restaurable. En pratique, la protection devient robuste quand les couches sont liées entre elles, ce qui suppose ensuite une mise en œuvre simple et disciplinée.
Comment la mettre en place sans bloquer les équipes
Je préfère toujours déployer la protection par étapes. Si l’on commence par des règles trop complexes, les équipes les contournent; si l’on commence par les bons fondamentaux, la sécurité monte sans dégrader la productivité.
- Cartographier les actifs et les données critiques. Je liste ce qui est indispensable au fonctionnement, ce qui contient des données sensibles et ce qui peut être coupé sans bloquer l’activité.
- Verrouiller l’identité. J’active la MFA sur la messagerie, le cloud, les accès distants et les comptes d’administration, et je vise des mots de passe ou phrases de passe d’au moins 12 caractères, uniques partout.
- Standardiser les postes. J’impose les mises à jour, le chiffrement du disque, l’EDR et une configuration commune via MDM ou équivalent.
- Isoler les sauvegardes. Je pars sur la règle 3-2-1, avec une copie hors ligne et des tests de restauration réguliers.
- Rendre les accès distants sobres. J’évite d’exposer des services directement sur Internet quand un VPN ou un ZTNA suffit, et je limite les comptes autorisés.
- Préparer l’incident. Je définis qui coupe quoi, qui décide, qui communique et comment conserver les preuves en cas d’attaque.
En 2026, si votre organisation entre dans le champ de NIS2, cette cartographie sert aussi de base de conformité: sans inventaire clair, sans preuves de contrôle et sans gestion d’incident, la sécurité reste difficile à défendre sur le plan opérationnel comme sur le plan réglementaire. Une fois cette base en place, il reste à éviter les erreurs classiques qui ruinent le travail déjà fait.
Les erreurs qui fragilisent encore trop souvent les organisations
- Confondre antivirus et stratégie de protection.
- Utiliser des comptes partagés ou laisser des identifiants circuler dans les équipes.
- Conserver des comptes administrateur utilisés au quotidien sur le poste principal.
- Reporter les correctifs parce qu’un système “fonctionne encore”.
- Stocker les sauvegardes sur le même domaine, le même NAS ou le même compte cloud que la production.
- Ne jamais tester la restauration ni les scénarios de reprise.
- Multiplier les outils sans responsable clairement nommé pour les piloter.
Le vrai problème n’est pas seulement technique: c’est le manque de discipline dans l’exploitation. Un dispositif peut être sophistiqué sur le papier et rester fragile si personne n’en vérifie régulièrement l’état, les alertes et les droits d’accès. C’est pour cela qu’il faut finir par une feuille de route très concrète.
La feuille de route que je recommande pour un gain rapide et durable
Si je devais repartir de zéro, je chercherais d’abord les trois gains les plus rentables, dans cet ordre.
- MFA partout sur la messagerie, le cloud, les VPN et les comptes d’administration.
- Sauvegardes 3-2-1 avec au moins une copie hors ligne et un test de restauration documenté.
- Correctifs prioritaires sur les systèmes exposés, puis sur les postes et serveurs moins critiques.
Ensuite seulement, j’irais vers la supervision plus avancée, la segmentation fine ou l’automatisation de la réponse. La logique est simple: on sécurise d’abord ce qui empêche l’attaque la plus probable de réussir, puis on ajoute les briques qui améliorent la détection et la résilience. C’est cette hiérarchie qui transforme une protection théorique en véritable capacité opérationnelle.