Les points essentiels à retenir sur le fonctionnement d’un data center
- Un centre de données héberge des serveurs, du stockage et des équipements réseau dans un environnement conçu pour rester disponible en permanence.
- La continuité repose sur une chaîne d’alimentation redondante, avec onduleurs, groupes électrogènes et distribution électrique séparée.
- Le refroidissement est aussi critique que l’énergie, car la densité de calcul produit beaucoup de chaleur et peut faire chuter les performances.
- La résilience vient de la redondance, de la supervision en temps réel et de procédures de maintenance testées.
- Dans le cloud, le data center n’est qu’une brique de l’ensemble: la vraie robustesse dépend aussi de la répartition géographique et des sauvegardes.
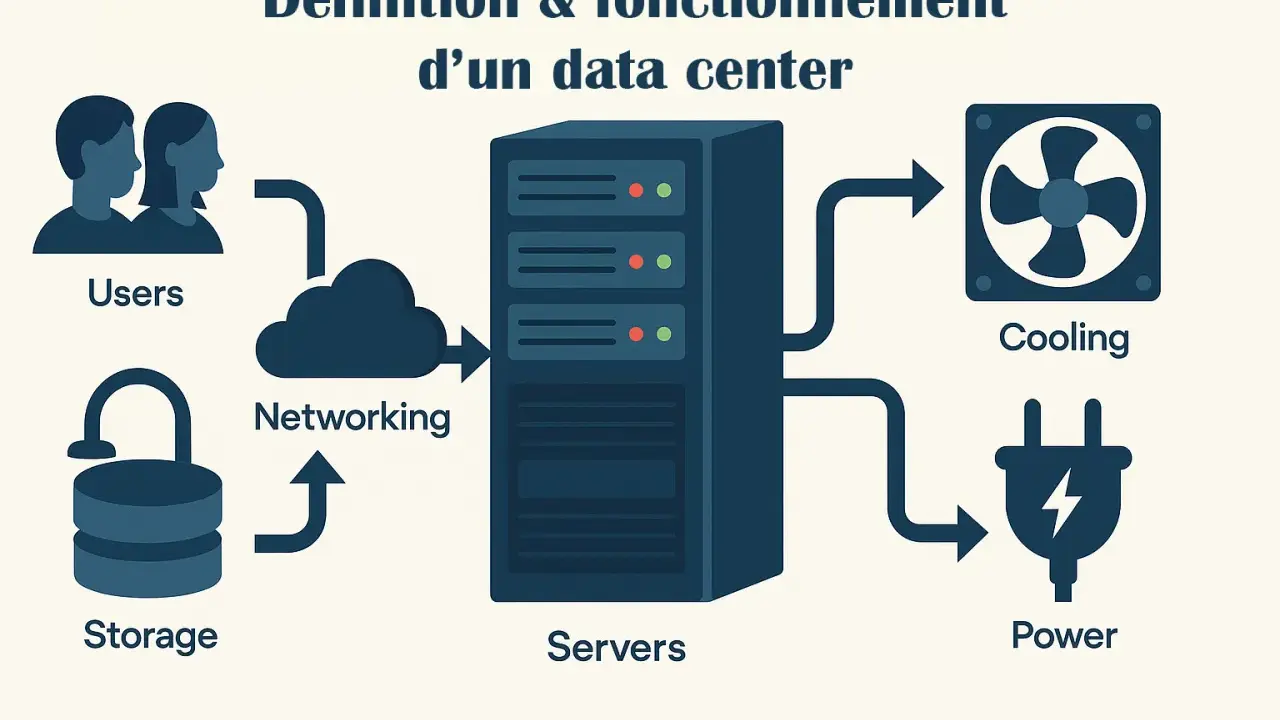
Ce qu’abrite réellement un centre de données
Quand j’explique l’architecture d’un centre de données, je commence toujours par séparer deux niveaux: la couche physique et la couche logique. La première regroupe les serveurs, les baies de stockage, les routeurs, les commutateurs et tout ce qui permet au matériel de tourner sans interruption. La seconde comprend la virtualisation, les systèmes d’exploitation, les applications et les outils d’orchestration qui répartissent les charges.
Dans une baie, on trouve rarement un seul type de machine. Les serveurs de calcul traitent les requêtes, les serveurs de stockage conservent les fichiers et les bases de données, et les équipements réseau font circuler les paquets entre ces briques. Au-dessus, un hyperviseur ou une plateforme de conteneurs permet souvent de faire tourner plusieurs environnements sur une même machine physique, ce qui améliore l’utilisation des ressources sans supprimer les contraintes matérielles.
- Serveurs pour exécuter les applications et les services métiers.
- Stockage pour conserver bases de données, sauvegardes et fichiers applicatifs.
- Réseau pour relier les machines entre elles et vers l’extérieur.
- Supervision pour surveiller les alertes, la charge, la température et les incidents.
Le point clé est simple: un data center n’héberge pas seulement des machines, il maintient un écosystème entier où chaque couche dépend de la suivante. C’est ce chemin interne qu’il faut avoir en tête avant de regarder comment une requête y circule réellement.
Le trajet d’une requête de bout en bout
Le fonctionnement devient beaucoup plus clair si l’on suit une demande utilisateur du début à la fin. Prenons un site web ou une application métier: le navigateur envoie une requête, le DNS la dirige vers la bonne adresse, puis un pare-feu ou un répartiteur de charge l’oriente vers un serveur disponible.
- Le client atteint le point d’entrée du service, souvent un load balancer ou une passerelle.
- La requête est répartie vers une instance applicative libre, ce qui évite de saturer une seule machine.
- L’application consulte éventuellement un cache, une base de données ou un stockage objet.
- Les journaux et les métriques sont enregistrés pour suivre la performance et détecter les anomalies.
- La réponse repart vers l’utilisateur, tandis que le système conserve l’état nécessaire pour la suite.
Ce parcours semble linéaire sur le papier, mais il repose en réalité sur plusieurs mécanismes de secours. Si une instance ne répond plus, l’orchestrateur peut en démarrer une autre; si un nœud réseau tombe, le trafic bascule vers un chemin différent. En pratique, c’est cette logique de bascule, plus que la puissance brute, qui fait la qualité d’un site.
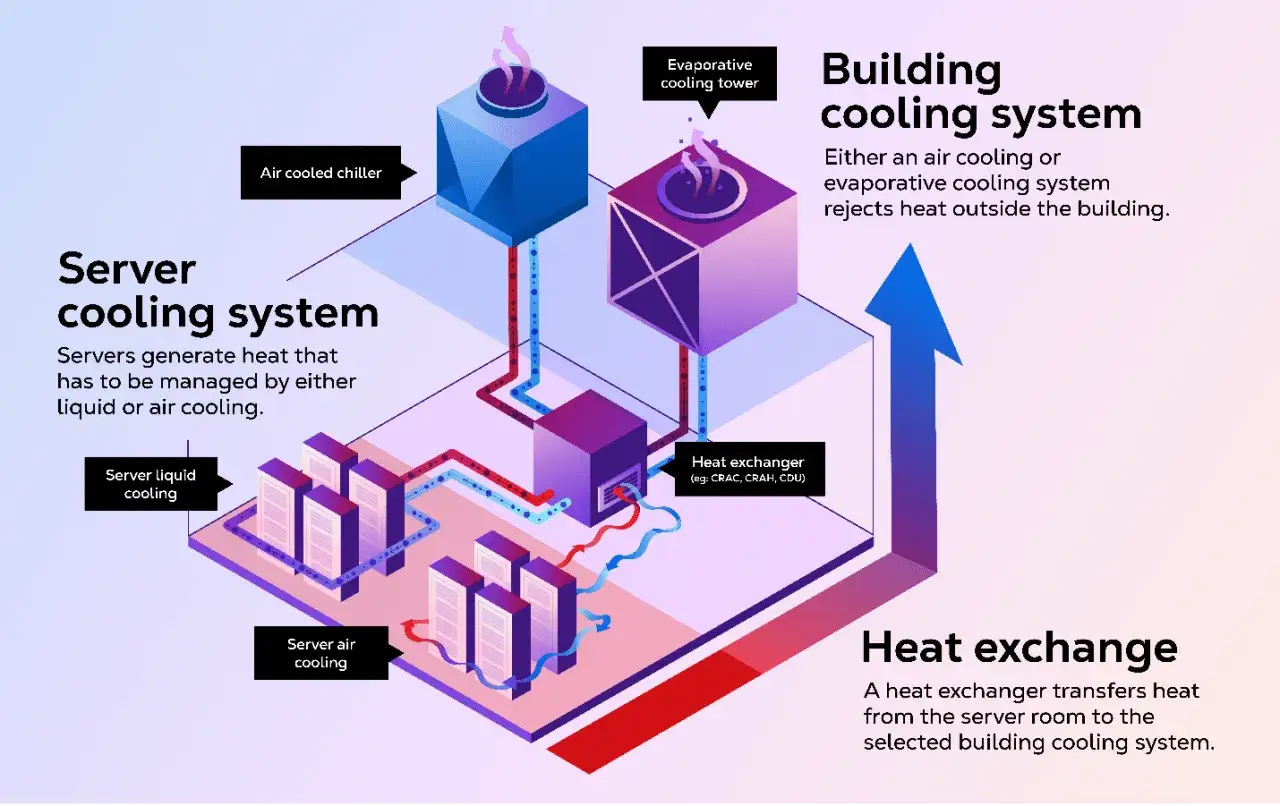
L’énergie et le refroidissement font tenir tout le reste
On sous-estime souvent le rôle de l’infrastructure électrique. Pourtant, sans énergie stable, un data center s’arrête immédiatement. La chaîne classique commence par le réseau électrique, passe par des onduleurs qui couvrent les microcoupures, puis bascule vers des groupes électrogènes en cas de coupure prolongée. L’idée n’est pas de fonctionner avec une seule source, mais d’éliminer les points de défaillance uniques.
La distribution interne est elle aussi redondée dans les sites sérieux. On parle fréquemment de architectures N+1 ou 2N, selon le niveau de duplication des équipements critiques. En langage simple, cela signifie qu’un composant peut tomber sans interrompre le service. Je considère que c’est l’une des différences les plus concrètes entre une salle serveur ordinaire et une vraie infrastructure de production.
Le refroidissement suit la même logique. Les serveurs transforment une partie de l’électricité en chaleur, et plus les charges sont denses, plus la contrainte thermique augmente. Les centres modernes utilisent des allées chaudes et froides, de la ventilation contrôlée, parfois du free cooling quand les conditions extérieures le permettent, et de plus en plus souvent du refroidissement liquide sur les charges très concentrées. En 2026, la montée des usages IA accélère clairement cette évolution.
- Allées froides et chaudes pour organiser le flux d’air et limiter les recirculations.
- Capteurs pour surveiller température, humidité et consommation.
- Redondance thermique pour maintenir la capacité même en cas de panne d’un circuit.
- Refroidissement liquide pour les baies très denses ou les charges lourdes.
Si l’énergie et la température sont maîtrisées, le site peut déjà tenir ses promesses de disponibilité. Mais cela ne suffit pas: il faut encore protéger physiquement et numériquement l’ensemble.
Sécurité, supervision et maintenance ne s’arrêtent jamais
Un data center fonctionne en continu parce qu’il est surveillé en continu. La sécurité physique commence à l’extérieur du bâtiment, avec le contrôle d’accès, les badges, parfois la biométrie, la vidéosurveillance et les zones cloisonnées. À l’intérieur, les équipes exploitent des journaux d’événements, des systèmes d’alerte et des procédures précises pour tout incident, du simple capteur en défaut à la panne plus sérieuse.
La sécurité logique est tout aussi importante. Les réseaux sont segmentés, les flux sont filtrés, les accès d’administration passent par des bastions ou des canaux très contrôlés, et les mises à jour sont planifiées pour éviter les interruptions inattendues. Je distingue toujours réplication et sauvegarde: la première sert surtout à garder un service disponible, la seconde à pouvoir revenir en arrière après une erreur humaine, un bug ou un ransomware.
En France, la conformité pèse aussi dans les choix d’infrastructure. La CNIL rappelle que la sécurité des données personnelles fait partie des obligations du RGPD, et l’ANSSI réserve SecNumCloud aux offres qui visent un niveau d’exigence élevé pour les usages sensibles. Concrètement, cela influence le cloisonnement des accès, les procédures d’exploitation et le choix des prestataires.
- Supervision 24/7 pour détecter les alertes avant l’incident visible.
- Tests de reprise pour vérifier qu’une panne ne casse pas la chaîne de service.
- Mises à jour contrôlées pour limiter les régressions lors des maintenances.
- Plans de continuité pour garder les services actifs pendant un sinistre.
Une fois ces bases en place, la vraie question devient le modèle d’hébergement à adopter, car tous les data centers ne répondent pas aux mêmes besoins.
Cloud, colocation ou salle serveur privée
Pour une entreprise, le choix n’est pas seulement technique. Il détermine aussi le niveau de contrôle, les coûts d’exploitation et la vitesse d’évolution. Je résume souvent le sujet ainsi: plus on veut de liberté matérielle, plus il faut assumer l’exploitation; plus on délègue, plus on gagne en agilité, mais on accepte une part de dépendance.
| Modèle | Qui possède le matériel | Avantage principal | Limite principale | Cas d’usage typique |
|---|---|---|---|---|
| Salle serveur privée | L’entreprise | Contrôle maximal | Maintenance lourde et coûts élevés | Environnements très spécifiques ou sensibles |
| Colocation | L’entreprise, dans un site tiers | Bon compromis entre contrôle et résilience | Il faut toujours gérer ses propres serveurs | SI critiques, réseaux hybrides, besoin de connectivité forte |
| Cloud public | Le fournisseur | Élasticité et déploiement rapide | Dépendance au prestataire et à l’architecture choisie | Applications variables, équipes DevOps, montée en charge rapide |
Dans le cloud, il faut aussi penser en termes de région et de zone de disponibilité, pas seulement en termes de machine. Une application critique ne devrait pas dépendre d’un seul site ni d’une seule copie de données. C’est précisément cette logique de répartition qui transforme un hébergement classique en architecture résiliente.
Les détails qui séparent un site robuste d’un site fragile
Quand je dois évaluer une infrastructure, je regarde d’abord ce qui se passe lorsqu’un composant tombe. Un site vraiment solide ne repose pas sur un seul lien réseau, une seule alimentation, une seule baie de stockage ou une seule procédure connue par une seule personne. Il est conçu pour absorber l’aléa sans faire remonter l’incident jusqu’à l’utilisateur final.- Alimentation double et chemins électriques séparés.
- Réseau redondé avec plusieurs opérateurs ou plusieurs chemins internes.
- Sauvegardes testées, pas seulement créées.
- Procédures documentées pour le basculement, la maintenance et le retour arrière.
- Mesures de performance suivies dans le temps, pas seulement lors des audits.
Au fond, le fonctionnement d’un data center repose sur une idée très simple: rien d’important ne doit dépendre d’un seul point de défaillance. C’est cette discipline de redondance, de supervision et d’anticipation qui permet à l’infrastructure de rester invisible pour l’utilisateur, donc réellement fiable.