Les repères essentiels pour décider sans confondre capacité et performance
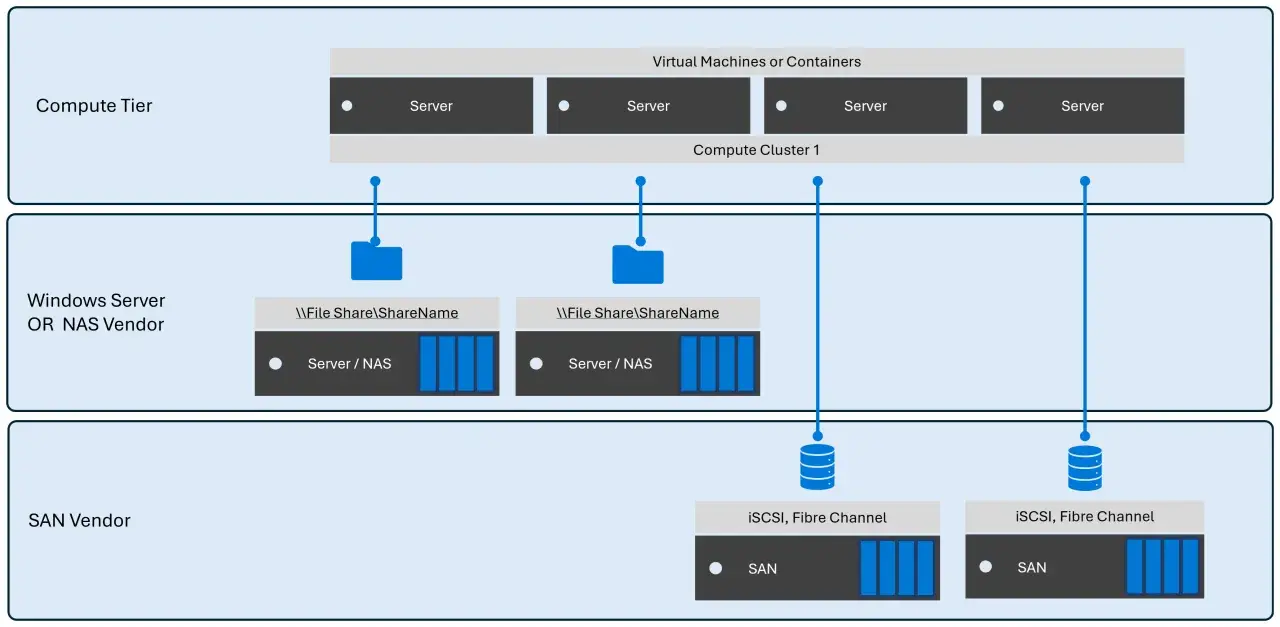
- Le SAN sert du stockage en mode bloc, pas du partage de fichiers comme un NAS.
- La fiabilité repose sur au moins 2 contrôleurs, 2 chemins réseau et un vrai multipathing côté hôte.
- Fibre Channel reste la valeur sûre pour les charges critiques, iSCSI limite le coût d’entrée, et NVMe-oF vise la meilleure latence.
- Le bon dimensionnement se fait en IOPS, en latence et en comportement d’écriture, pas seulement en téraoctets.
- Dans un contexte cloud hybride, la baie sert surtout de base locale rapide, puis de source de réplication ou de tiering.
- Les erreurs les plus coûteuses viennent presque toujours d’un manque de redondance ou d’une compatibilité mal vérifiée.
Ce qu’une baie de stockage SAN embarque vraiment
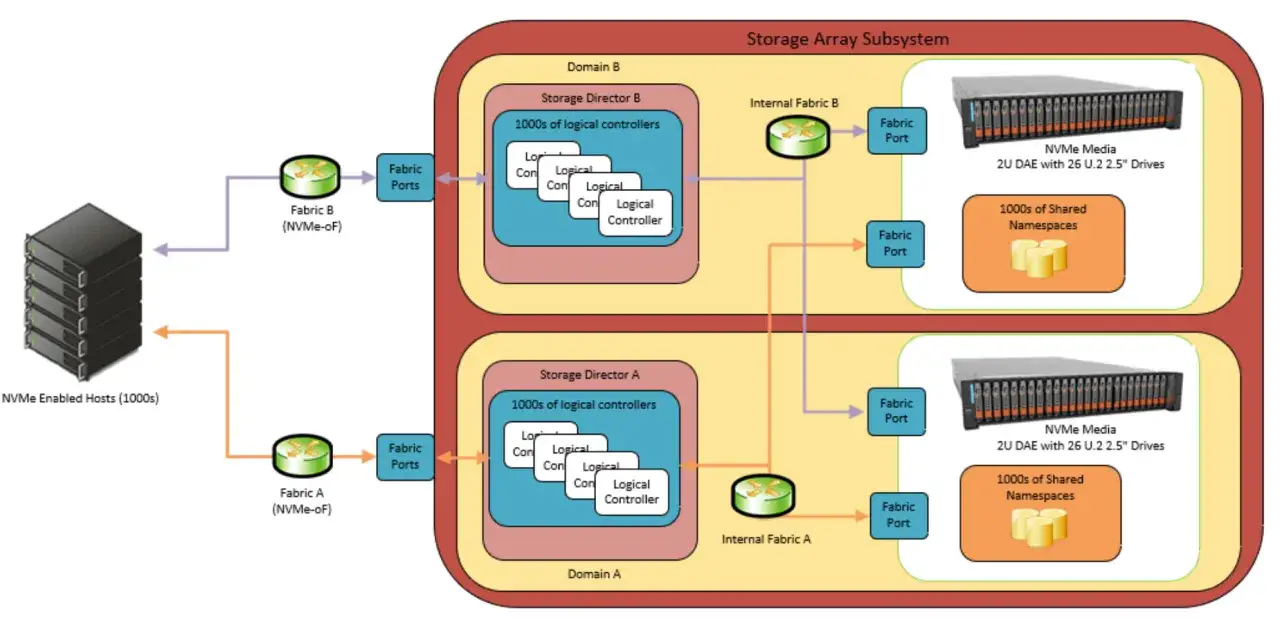
Dans le jargon, on parle de baie, de baie de stockage ou de système SAN, mais la logique est toujours la même: des disques ou SSD sont pilotés par des contrôleurs qui exposent des volumes logiques aux hôtes. Ce qui fait la qualité d’une architecture, ce n’est pas seulement la capacité brute. C’est la manière dont la baie gère le cache, le RAID, les ports d’accès, la réplication et le basculement.| Composant | Rôle | Point d’attention |
|---|---|---|
| Contrôleurs | Ils orchestrent les volumes, le cache, le RAID et le failover. | Je privilégie une architecture à double contrôleur pour éviter un point unique de défaillance. |
| Disques et SSD | Ils fournissent la capacité et les IOPS. | Les SSD réduisent la latence; les HDD restent utiles quand le coût par téraoctet prime. |
| Cache mémoire | Il absorbe les pics de lecture et d’écriture. | Sa protection est cruciale, surtout pour les écritures synchrones. |
| Ports hôtes | Ils relient la baie au réseau SAN. | Il faut vérifier la compatibilité avec les HBA, les NIC et les optiques du reste du parc. |
| Châssis d’extension | Ils ajoutent des tiroirs de disques sans redessiner toute la baie. | Je regarde toujours la capacité d’extension réelle, pas seulement le chiffrage commercial. |
| Logiciel embarqué | Il pilote les snapshots, la réplication, la surveillance et l’automatisation. | Une baie mal maintenue sur le plan firmware devient vite un risque d’exploitation. |
Trois notions reviennent sans cesse. Une LUN est le volume logique présenté à l’hôte. Le zoning limite quels serveurs voient quels ports du fabric. Le masking contrôle quels volumes sont autorisés pour quel serveur. En face, le multipathing côté système d’exploitation garde plusieurs chemins actifs vers la baie, ce qui permet de survivre à la panne d’un câble, d’un port ou d’un contrôleur. Une architecture peut paraître rapide sur une fiche technique et rester fragile si ces briques sont mal alignées. Une fois cette base comprise, la vraie question devient celle du transport entre l’hôte et les disques.
Les protocoles qui comptent vraiment
Le SAN n’est pas un protocole unique, c’est une famille de transports. En pratique, trois options dominent encore les choix d’infrastructure: Fibre Channel, iSCSI et NVMe-oF. Je regarde toujours le compromis entre latence, simplicité d’exploitation et coût d’entrée, parce que le meilleur protocole sur le papier n’est pas toujours le plus rationnel dans une salle serveurs.
| Protocole | Ce qu’il apporte | Ses limites | Quand je le recommande |
|---|---|---|---|
| Fibre Channel | Latence prévisible, trafic isolé, maturité élevée. | Coût matériel plus élevé et compétences plus spécialisées. | Charges critiques, bases de données, virtualisation dense, environnements très sensibles à la stabilité. |
| iSCSI | Réutilise l’Ethernet existant et réduit le coût de démarrage. | Sensible à la congestion et aux erreurs de design réseau. | Sites de taille intermédiaire, budgets contenus, infrastructures déjà très Ethernet. |
| NVMe-oF | Très bon parallélisme et latence réduite pour les SSD modernes. | Exige un réseau propre, des versions compatibles et une exploitation plus rigoureuse. | Baies tout-flash, applications très I/O, environnements où chaque microseconde compte. |
NVMe-oF n’est pas un seul transport: il peut passer par Fibre Channel, par TCP ou par des variantes RDMA. C’est intéressant, mais pas magique. Si l’environnement est mal gouverné, le gain théorique s’écrase vite sous les erreurs de configuration, les pilotes hétérogènes ou les switches surchargés. Je ne mets pas FCoE au cœur d’un nouveau projet sauf contrainte d’existant; en 2026, je le vois surtout comme une option de convergence dans des architectures déjà très structurées. Le vrai sujet devient alors l’usage de la baie dans une infrastructure cloud hybride.
Quand le SAN devient un socle cloud hybride
Le cloud n’a pas fait disparaître le SAN. Il a déplacé son rôle. On garde la baie pour la couche bloc la plus sensible, puis on l’utilise comme source de réplication, de snapshot ou de tiering vers un site secondaire, une infrastructure de secours ou un stockage objet pour les données moins chaudes.
- Machines virtuelles et bases de données : je réserve la baie aux workloads qui ont besoin d’un accès bloc rapide et prévisible, surtout quand plusieurs hôtes se partagent les mêmes datastores.
- Reprise après sinistre : la réplication asynchrone ou synchrone sert à tenir un RPO maîtrisé, c’est-à-dire une perte de données acceptable limitée, tandis que le RTO mesure le temps pour remettre le service en ligne.
- Tiering : je garde les données actives sur la baie principale et j’envoie les jeux froids vers une couche moins coûteuse, ce qui évite de payer du flash pour tout.
- Automatisation : les API de provisioning, les scripts d’exploitation et l’intégration avec les hyperviseurs réduisent les erreurs humaines et accélèrent les ouvertures de volumes.
Le point le plus important, à mes yeux, c’est que le cloud change la gouvernance plus que la mécanique de stockage. On ne demande pas à une baie de tout faire, on lui demande d’être le noyau rapide et fiable d’un ensemble plus large. C’est là que les erreurs d’architecture deviennent visibles.
Les erreurs d’architecture qui coûtent le plus cher
Les incidents graves viennent rarement d’un manque de capacité brute. Ils viennent plutôt d’un mauvais arbitrage au départ, puis d’une exploitation qui n’a pas été testée dans des conditions réelles.
- Dimensionner seulement en téraoctets : une baie peut avoir encore beaucoup d’espace libre et être déjà saturée en IOPS ou en latence.
- Oublier la redondance des fabrics : un seul switch, un seul chemin ou un seul jeu d’optiques suffit à créer un point de défaillance inutile.
- Mélanger des charges incompatibles : une base transactionnelle très écrite et une archive froide ne se comportent pas de la même façon sur le même pool.
- Négliger les firmwares et les pilotes : HBA, NIC, contrôleurs et systèmes d’exploitation doivent être vérifiés comme un ensemble, pas chacun isolément.
- Choisir un RAID pour de mauvaises raisons : RAID 6 rassure sur la capacité, mais RAID 10 garde souvent l’avantage sur des écritures très soutenues.
- Ne jamais tester le failover : une redondance non vérifiée reste une hypothèse, pas une garantie.
Les équipes qui s’en sortent le mieux sont celles qui testent la panne d’un port, d’un contrôleur et d’un chemin réseau avant la mise en production, pas après. À partir de là, il reste une question très concrète: comment choisir une plateforme qui tiendra dans la durée sans alourdir l’exploitation ?
Ce que je vérifierais avant d’acheter ou de moderniser en 2026
En 2026, je regarde systématiquement cinq critères avant de valider une baie: la charge réelle, la résilience, l’exploitation, la sécurité et l’intégration cloud. C’est plus utile qu’une fiche marketing qui ne parle que de capacité maximale.
| Critère | Ce que je demande | Pourquoi |
|---|---|---|
| Profil d’E/S | IOPS, latence cible, ratio lecture/écriture, croissance mensuelle. | Le dimensionnement doit suivre le comportement réel des applications, pas un simple volume de données. |
| Résilience | 2 contrôleurs, 2 fabrics, alimentation redondante, tests de basculement. | La continuité de service dépend de la suppression des points uniques de défaillance. |
| Compatibilité | HBA, NIC, hyperviseurs, OS, pilotes, versions firmware. | Un écosystème mal aligné crée des pannes difficiles à diagnostiquer. |
| Exploitation | API, supervision, alerting, mises à jour sans interruption si possible. | Une baie trop complexe coûte plus cher à exploiter qu’à acheter. |
| Sécurité et cloud | Chiffrement au repos, snapshots, réplication distante, intégration avec la sauvegarde et le site secondaire. | Le stockage doit s’inscrire dans un plan de continuité, pas fonctionner en silo. |
Si je devais retenir une seule règle, ce serait celle-ci: une bonne baie SAN n’est pas celle qui affiche le plus de téraoctets, mais celle qui reste prévisible sous charge, simple à faire évoluer et solide quand un composant tombe. C’est cette prévisibilité qui fait la différence entre un stockage qu’on subit et une infrastructure qu’on maîtrise.