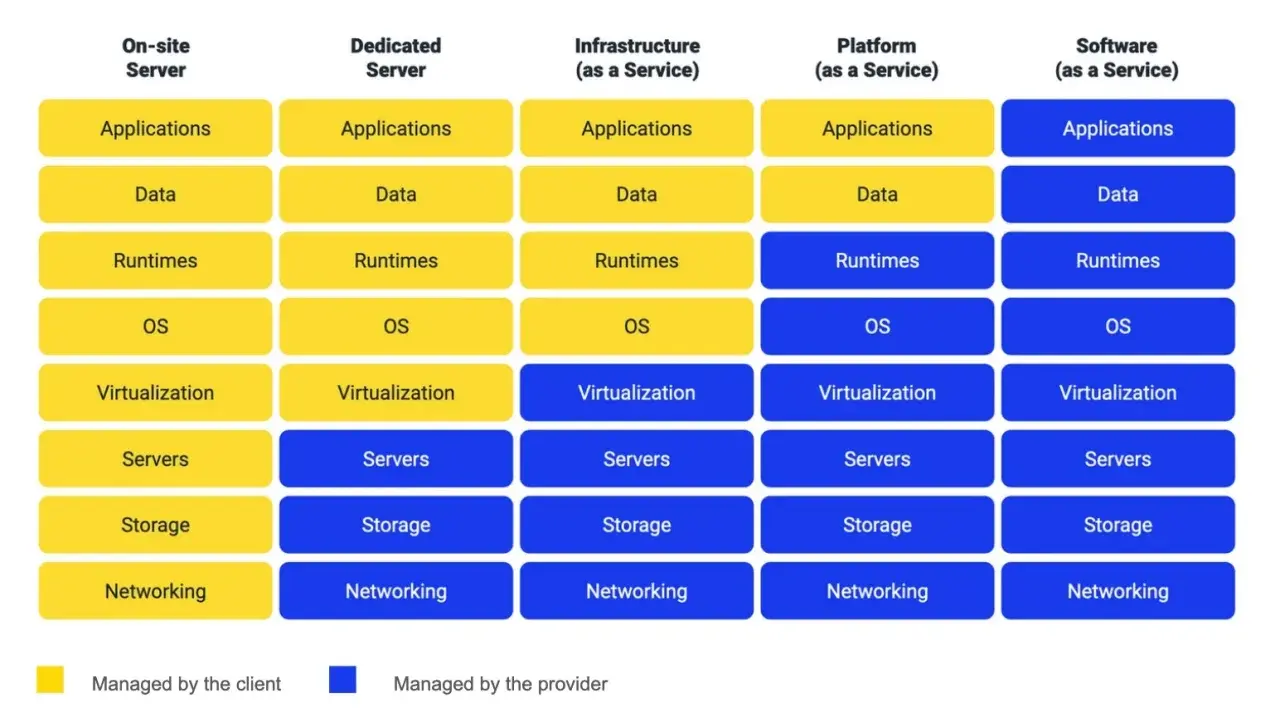
Ce qu’il faut retenir avant de choisir une architecture serveur
- Un serveur fournit des services à d’autres machines, mais en cloud il s’inscrit toujours dans un ensemble plus large: stockage, réseau, virtualisation et supervision.
- Le bon choix dépend surtout de la charge, de la sensibilité des données, du niveau de contrôle attendu et de la compétence de l’équipe.
- Un serveur virtuel apporte de la souplesse, tandis qu’un bare metal favorise le contrôle et la performance brute.
- Le cloud simplifie le déploiement, mais il ne supprime ni les besoins de sécurité, ni les sauvegardes, ni le suivi des coûts.
- Le plus gros piège reste de surdimensionner l’infrastructure ou de confondre rapidité de mise en ligne et solidité d’exploitation.
Ce qu’est un serveur et pourquoi il reste central
Je résume la base simplement: un serveur est un système informatique conçu pour répondre à des requêtes et fournir un service, qu’il s’agisse d’héberger un site web, d’exécuter une application métier, de servir une base de données ou de gérer l’authentification. Dans un modèle client-serveur, l’utilisateur ou le logiciel client demande, et la machine serveur traite, répond et distribue les ressources.
Ce rôle reste central même dans le cloud, parce qu’on ne supprime pas la logique serveur; on change surtout la manière de la consommer. Le serveur peut être physique, virtuel ou entièrement géré par un fournisseur, mais sa fonction reste la même: exécuter une charge de travail de manière fiable.
- Applications web : pages, API, contenus dynamiques, formulaires, échanges temps réel.
- Bases de données : stockage, lecture, écriture, réplication, indexation.
- Services d’entreprise : fichiers, messagerie, ERP, annuaire, authentification.
- Calcul et traitement : analyse de données, automatisations, batch, IA selon les cas d’usage.
À ce stade, le vrai sujet n’est donc pas seulement de savoir ce qu’est une machine, mais de comprendre quelle forme de serveur sert le mieux un besoin précis.
Les principales formes de serveurs à connaître
Quand j’évalue une infrastructure, je ne parle jamais du serveur comme d’un bloc unique. Il existe plusieurs approches, et chacune change le niveau de contrôle, la souplesse et le coût d’exploitation.
| Type | Atouts | Limites | Usage le plus courant |
|---|---|---|---|
| Serveur physique sur site | Contrôle total, isolation forte, architecture prévisible | Investissement initial élevé, maintenance interne, capacité plus rigide | Environnements stables, contraintes spécifiques, systèmes historiques |
| Serveur virtuel | Déploiement rapide, coûts flexibles, bonne mutualisation | Partage de ressources, performance moins constante qu’un dédié | Sites web, environnements de test, applications généralistes |
| Serveur cloud | Montée en charge à la demande, paiement à l’usage, automatisation | Dépendance au fournisseur, vigilance sur les coûts annexes | Applications variables, projets en croissance, services distribués |
| Bare metal | Machine dédiée, performances élevées, contrôle fin du matériel | Moins élastique qu’une instance virtuelle, configuration parfois plus exigeante | Charges lourdes, bases de données critiques, traitement intensif |
| Serverless | Gestion d’infrastructure réduite au minimum, facturation à l’exécution | Moins adapté aux traitements longs ou très spécialisés | Fonctions événementielles, automatisations, API légères |
En pratique, le bare metal reste intéressant quand la performance et l’isolement priment. Certains profils préconfigurés sont d’ailleurs provisionnables en quelques minutes chez certains fournisseurs cloud, ce qui rapproche l’expérience de celle d’une instance classique tout en gardant la puissance d’une machine dédiée. À l’inverse, le serverless ne remplace pas un serveur au sens strict, mais il permet d’externaliser une partie importante de l’exploitation.
Autrement dit, choisir un serveur revient moins à choisir une machine qu’à choisir un mode d’exploitation.
Comment choisir entre performance, souplesse et contrôle
Je vois trop souvent des équipes choisir d’abord la technologie, puis essayer de lui trouver un usage. L’ordre devrait être l’inverse: partir du besoin réel, puis remonter vers l’architecture.
Voici les critères qui font vraiment la différence:
- Stabilité de la charge : si l’activité est régulière et prévisible, un serveur dédié ou bare metal peut être pertinent; si la charge varie fortement, la virtualisation ou le cloud public sont souvent plus efficaces.
- Sensibilité des données : pour des données personnelles, financières ou réglementées, je regarde en priorité l’isolation, la localisation de l’hébergement et les mécanismes d’accès.
- Latence : pour des usages proches des utilisateurs ou des systèmes temps réel, la distance géographique et l’architecture réseau comptent autant que la puissance brute.
- Budget global : le coût ne se limite jamais à la machine; il faut aussi intégrer le stockage, le trafic sortant, la supervision, les sauvegardes et le temps d’administration.
- Compétences de l’équipe : une infrastructure simple à opérer vaut souvent mieux qu’une architecture théoriquement élégante mais mal maintenue.
Pour une PME ou une équipe IT légère, je conseille souvent une approche progressive: commencer par une instance virtuelle bien dimensionnée, ajouter des sauvegardes automatiques, puis isoler les services critiques au fur et à mesure. Pour une application très stable et gourmande, le bare metal redevient vite pertinent, surtout si le besoin est durable et que la performance doit rester constante.
Si vous traitez des données sensibles en France ou dans l’Union européenne, ajoutez une couche de réflexion sur la souveraineté, les responsabilités contractuelles et la séparation des environnements de test, de préproduction et de production.
Une fois le bon type de machine identifié, il faut encore comprendre ce que l’infrastructure cloud change concrètement au quotidien.Ce que change vraiment l’infrastructure cloud
Dans le cloud, le serveur n’est qu’une brique parmi d’autres. L’ensemble repose aussi sur le stockage, le réseau, la virtualisation, les sauvegardes, la supervision et l’automatisation. C’est cette combinaison qui apporte la souplesse promise par le cloud, pas la machine seule.
On parle souvent d’IaaS, de PaaS ou de SaaS, et ces sigles méritent une lecture pratique. Avec l’IaaS, vous gérez encore une partie de l’infrastructure. Avec le PaaS, vous déléguez davantage la couche technique. Avec le SaaS, vous consommez directement un logiciel prêt à l’emploi. Plus on monte dans l’abstraction, moins on administre l’infrastructure, mais plus on accepte le cadre imposé par le fournisseur.
La virtualisation joue ici un rôle clé: un hyperviseur répartit les ressources d’une machine physique entre plusieurs machines virtuelles. C’est ce qui permet d’optimiser l’usage du matériel, d’augmenter la densité de déploiement et de créer ou supprimer des environnements rapidement. Le revers, c’est qu’il faut surveiller la contention de ressources, les dépendances réseau et les effets de voisinage dans les plateformes partagées.
En exploitation réelle, trois fonctions font souvent la différence:
- Le load balancing : il répartit les requêtes entre plusieurs nœuds pour éviter qu’un seul serveur devienne un point de saturation.
- Les snapshots et sauvegardes : ils permettent de revenir en arrière rapidement après une erreur, une panne ou une mise à jour ratée.
- La supervision : elle mesure l’usage CPU, mémoire, disque, réseau et alerte avant que la dégradation ne devienne visible pour l’utilisateur.
Le point que je rappelle presque toujours est le suivant: le cloud simplifie le déploiement, mais il ne dispense pas de piloter correctement la sécurité, les coûts et la disponibilité.
Cette réalité amène naturellement à regarder les erreurs les plus fréquentes, parce qu’elles coûtent souvent plus cher que le choix technique initial.
Les erreurs qui coûtent le plus cher
Je retrouve les mêmes pièges dans beaucoup de projets, quel que soit le secteur. Ils ne sont pas spectaculaires, mais ils dégradent vite la qualité de service et la facture.
- Surdimensionner dès le départ : beaucoup d’équipes prennent une instance trop puissante “par sécurité”, puis paient pendant des mois pour une capacité inutilisée.
- Confondre disponibilité et sauvegarde : un serveur peut être disponible et pourtant contenir des données irrécupérables si la stratégie de backup est faible.
- Ignorer le trafic sortant : le coût réseau est souvent sous-estimé, alors qu’il peut peser lourd sur une architecture très bavarde.
- Oublier les mises à jour : un serveur non patché devient une cible simple, surtout lorsqu’il est exposé à Internet.
- Tout centraliser sur une seule machine : une panne unique peut alors arrêter l’ensemble du service.
- Ne pas tester la restauration : une sauvegarde qui n’a jamais été restaurée est une hypothèse, pas une garantie.
Le meilleur moyen d’éviter ces dérives reste de raisonner en services, pas en machines isolées. Un serveur doit être intégré à une stratégie plus large de sécurité, de continuité et de supervision.
À partir de là, la dernière étape consiste à mettre en place quelques règles simples avant même le déploiement.
Ce que je recommande de préparer avant le déploiement
Quand je construis ou révise une architecture, je préfère toujours sécuriser les bases avant d’ajouter des couches de complexité. C’est la différence entre une infrastructure qui tient dans la durée et une infrastructure qui accumule des rustines.
- Définir la charge cible, le pic d’utilisation et le niveau de croissance attendu.
- Isoler les environnements de développement, de test et de production.
- Mettre en place une stratégie de sauvegarde avec test de restauration.
- Configurer la journalisation et la supervision dès le premier jour.
- Limiter les droits d’accès avec une gestion stricte des identités.
- Prévoir des seuils budgétaires et des alertes sur la consommation.
- Documenter le plan de reprise après incident, même pour une petite infrastructure.