L’essentiel à retenir avant de choisir une architecture
- Un serveur peut être physique, virtuel ou entièrement géré dans le cloud, et le bon choix dépend surtout de la charge et du niveau d’autonomie voulu.
- Le duo DNS + HTTP explique la majorité du trajet entre le navigateur et la ressource demandée.
- Le cloud apporte surtout de l’élasticité, de l’automatisation et une mise à disposition rapide, pas une magie automatique sur les coûts.
- La sécurité utile commence par TLS, les mises à jour, les sauvegardes testées et une supervision sérieuse.
- Les pannes les plus coûteuses viennent souvent d’une mauvaise séparation des rôles et d’un manque de visibilité.
Ce que recouvre vraiment un serveur connecté au réseau
Je distingue toujours deux réalités qui se superposent souvent dans les discussions: le matériel et le service. Le matériel, c’est la machine physique, avec son processeur, sa mémoire, son stockage et son réseau. Le service, c’est le logiciel qui écoute les demandes et décide quoi renvoyer. Dans la pratique, un même serveur peut héberger un site web, une API, une base de données ou un service interne, mais chaque rôle impose des contraintes différentes.
Le point important est simple: les clients demandent, le serveur répond. Un navigateur, une application mobile ou un logiciel métier se comporte comme un client. Il envoie une requête, puis attend une réponse sous une forme exploitable. Quand on parle de serveur web, on pense souvent à la page visible par l’utilisateur final, mais l’infrastructure réelle est plus large: il y a presque toujours une couche web, une couche applicative et parfois une couche de données séparée.
Je vois encore beaucoup de confusions entre “serveur”, “machine”, “hébergement” et “service”. Or cette distinction change tout quand il faut dépanner ou faire évoluer une architecture. Si le problème vient du matériel, on ne traite pas la panne comme un souci applicatif. Si le problème vient du code ou de la configuration, changer de machine ne résout rien. Une fois cette base posée, on peut regarder le trajet réel d’une requête pour comprendre où se joue la vitesse de réponse.
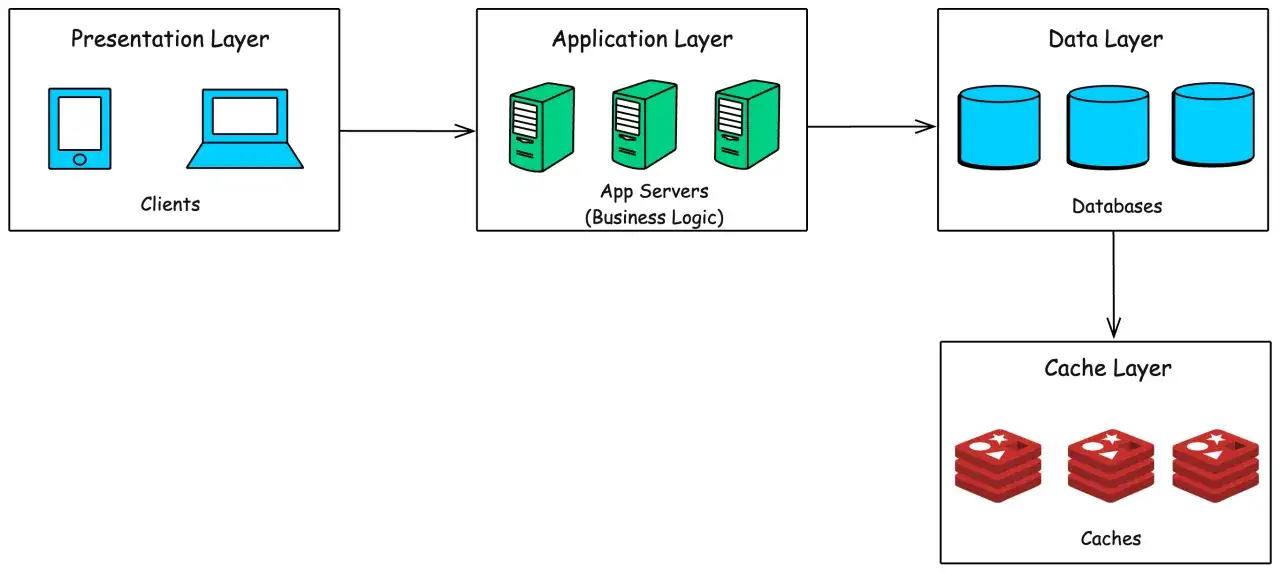
Le chemin d’une requête du navigateur à la réponse
Quand un utilisateur saisit une adresse dans son navigateur, le premier acteur important n’est pas le serveur lui-même, mais le DNS. Son rôle consiste à traduire un nom de domaine en adresse IP. C’est cette traduction qui permet au navigateur de trouver la bonne machine ou le bon point d’entrée du service. Sans cette étape, le nom est lisible pour un humain, mais inutilisable pour le réseau.
Ensuite intervient HTTP, ou plus exactement HTTPS dans la plupart des environnements sérieux. HTTP fonctionne sur un modèle de requête-réponse: le client demande une ressource, le serveur la traite, puis renvoie un contenu, un statut ou une redirection. Avec HTTPS, la couche TLS chiffre les échanges et protège les données en transit. Dans la réalité, c’est un point non négociable dès qu’il y a de l’authentification, des formulaires, des cookies ou des données métier.
Dans les architectures cloud modernes, je regarde aussi ce qui se passe avant d’atteindre le serveur d’origine. Un reverse proxy peut terminer le chiffrement, filtrer certaines requêtes et répartir la charge. Un CDN peut servir des fichiers statiques depuis un nœud proche de l’utilisateur. Ces couches ne sont pas des accessoires: elles réduisent la latence, absorbent une partie des pics et évitent d’exposer directement le cœur du système. C’est précisément ce flux qui influence le choix de l’hébergement, car la meilleure machine n’est pas forcément la meilleure architecture.
Les modèles d’hébergement qui comptent en cloud
Quand je compare les options, je ne pars pas d’abord de la marque du fournisseur. Je pars du niveau de contrôle nécessaire, du budget d’exploitation et du temps que l’équipe est prête à consacrer à l’administration. Dans beaucoup de cas, le vrai choix se fait entre simplicité opérationnelle et maîtrise fine de l’environnement.
| Modèle | Ce que c’est | Atouts | Limites | Quand je le recommande |
|---|---|---|---|---|
| Serveur physique dédié | Une machine entière réservée à un seul usage | Contrôle maximal, isolation claire, performances prévisibles | Moins flexible, mise à l’échelle lente, administration plus lourde | Charges stables, besoins spécifiques, contraintes fortes de sécurité ou de conformité |
| VPS ou machine virtuelle | Une instance isolée créée sur un serveur physique partagé | Bon compromis entre coût, souplesse et vitesse de déploiement | Ressources partagées, compétences d’administration encore nécessaires | Sites, API et applications qui ont besoin d’un environnement maîtrisé sans complexité excessive |
| Cloud public | Ressources à la demande, facturées selon l’usage | Élasticité, automatisation, montée en charge rapide | Coûts qui montent vite si l’on surveille mal, architecture parfois plus complexe | Charges variables, croissance rapide, besoins de haute disponibilité |
| PaaS ou service managé | Le fournisseur gère une partie importante de la pile | Moins d’exploitation, déploiement plus rapide, réduction du travail de maintenance | Moins de liberté, dépendance plus forte à la plateforme | Équipes qui veulent livrer vite sans gérer toute l’infrastructure |
| Hybride ou privé | Mélange de ressources internes et cloud, parfois dédié à une organisation | Contrôle, intégration avec l’existant, meilleure adaptation à certaines contraintes | Architecture plus sophistiquée, gouvernance plus exigeante | Données sensibles, exigences réglementaires, systèmes hérités à conserver |
Les critères qui tranchent vraiment au moment de choisir
Quand j’évalue une architecture, je me pose presque toujours les mêmes questions. Pas parce qu’elles sont théoriques, mais parce qu’elles évitent les mauvaises surprises trois mois après la mise en ligne.
- La charge est-elle stable ou variable ? Une charge stable supporte bien un serveur dimensionné proprement. Une charge irrégulière bénéficie davantage de l’élasticité cloud.
- Quelle est la sensibilité des données ? Si les données sont sensibles ou soumises à des obligations fortes, je regarde la localisation, les contrats, le chiffrement et la répartition des accès.
- Quelle latence est acceptable ? Pour un service utilisé en France et en Europe, la région d’hébergement et la proximité des ressources influencent directement l’expérience.
- Combien de temps l’équipe peut-elle consacrer à l’exploitation ? Une petite équipe gagne souvent à déléguer une partie de la pile plutôt qu’à tout administrer seule.
- Quels sont les objectifs de reprise ? Le RTO, c’est le temps maximal d’indisponibilité acceptable. Le RPO, c’est la perte de données tolérable. Ces deux indicateurs sont plus utiles qu’un discours abstrait sur la “résilience”.
Les erreurs qui fragilisent le plus une mise en production
Je retrouve souvent les mêmes mauvaises habitudes, quel que soit le secteur. Elles ne paraissent pas graves au départ, puis elles deviennent coûteuses dès que le trafic augmente ou qu’un incident survient.
| Erreur fréquente | Effet réel | Correction plus solide |
|---|---|---|
| Tout faire tourner sur la même instance | Un seul incident peut couper le site, l’API et la base de données en même temps | Séparer les rôles et isoler au moins la couche de données |
| Négliger les sauvegardes testées | La restauration échoue au moment où elle devient critique | Automatiser les sauvegardes et vérifier régulièrement la remise en ligne |
| Exposer directement la base de données | Surface d’attaque plus large et risque d’erreur de configuration | Limiter l’accès au strict nécessaire, via des règles réseau précises |
| Ignorer les logs et les métriques | Les incidents sont détectés trop tard et l’analyse prend des heures | Mettre en place supervision, alertes et historisation des événements |
| Reporter les mises à jour | Accumulation de vulnérabilités et correctifs plus risqués à appliquer | Planifier des fenêtres de maintenance courtes mais régulières |
| Oublier TLS ou mal gérer les certificats | Exposition des échanges et problèmes de confiance côté navigateur | Chiffrer systématiquement les flux publics et automatiser le renouvellement |
Le problème n’est pas seulement technique. C’est souvent un problème de méthode. Une architecture peut sembler “fonctionner” tant qu’elle reste petite, puis s’effondrer dès qu’elle doit encaisser un pic, un déploiement raté ou une panne réseau. C’est pour cela que je préfère des systèmes un peu plus simples mais bien documentés, plutôt qu’une empilement d’outils dont personne ne maîtrise vraiment les dépendances.
La règle simple que je garde pour bâtir une base solide
Quand je dois résumer ma méthode en une phrase, je dis toujours la même chose: séparer, automatiser, observer. Séparer les rôles pour limiter l’impact d’une panne. Automatiser les déploiements, les sauvegardes et les vérifications récurrentes. Observer avec des journaux, des métriques et des alertes qui déclenchent une vraie réaction, pas seulement un bruit de plus dans une boîte mail.
À partir de là, tout devient plus lisible. On peut faire évoluer un service sans tout reconstruire, changer de fournisseur sans perdre la trace des dépendances critiques, et absorber une croissance modérée sans improvisation permanente. C’est souvent cette discipline discrète qui distingue une infrastructure “qui marche” d’une infrastructure réellement exploitable dans la durée.
Si je devais retenir une seule idée, ce serait celle-ci: un serveur bien choisi n’est pas forcément le plus puissant, mais celui qui correspond à la charge, au niveau de risque et à la maturité de l’équipe. C’est là que le cloud devient utile, non pas comme slogan, mais comme levier concret pour livrer vite, garder le contrôle et rester capable de grandir sans rupture.