Une stratégie hybride n’a de sens que si elle résout un vrai problème métier: garder certaines applications au plus près des données, réduire la latence, ou répondre à des contraintes de souveraineté sans renoncer aux outils du cloud. C’est précisément le rôle d’Azure Local, l’évolution actuelle de la gamme autrefois connue sous le nom d’Azure Stack HCI. Dans cet article, je détaille son fonctionnement, ses cas d’usage les plus solides, son coût réel et les points à vérifier avant de la mettre en production.
Les points clés à garder en tête avant de choisir Azure Local
- La plateforme étend Azure vers des environnements que vous contrôlez, tout en gardant une gestion unifiée via Azure Arc.
- Elle vise surtout les charges sensibles à la latence, à la continuité de service et à la résidence des données.
- La facturation repose sur les cœurs physiques, pas sur le nombre de machines virtuelles.
- On peut démarrer très petit, mais le bon dimensionnement dépend surtout du réseau, du matériel validé et de l’exploitation au quotidien.
- Le principal risque n’est pas technique au sens strict, il vient souvent d’un mauvais cadrage du besoin ou d’un matériel mal choisi.
Ce que recouvre réellement Azure Local
Je résume la solution comme une extension d’Azure vers des machines installées chez vous, dans une agence, un atelier, un site distant ou un datacenter privé. L’idée n’est pas de remplacer le cloud public, mais de faire tourner localement des charges modernes et traditionnelles avec une expérience de gestion proche d’Azure.
Concrètement, la plateforme s’appuie sur Azure Arc comme plan de contrôle unifié. Vous pilotez vos ressources via le portail Azure, l’interface de ligne de commande Azure, les modèles ARM, et selon les cas avec Windows Admin Center ou PowerShell. C’est important, parce que la promesse n’est pas seulement d’exécuter des VM: elle consiste aussi à garder une gouvernance cohérente entre local et cloud.
Autre point utile à clarifier: Azure Local fonctionne sur du matériel validé et peut être utilisé en mode connecté ou déconnecté, selon vos contraintes. On n’est donc pas face à une simple pile de virtualisation locale, mais à une infrastructure hybride pensée pour s’insérer dans une stratégie Azure plus large.
La vraie question n’est donc pas seulement ce que c’est, mais surtout dans quels cas cette approche est plus pertinente qu’un Azure public ou qu’une virtualisation classique.
Quand cette approche vaut mieux que le cloud public ou la virtualisation classique
Le choix devient clair quand on compare les objectifs réels. Si tout doit rester dans Azure, avec une élasticité maximale et une forte dépendance aux services managés, le cloud public reste plus simple. Si vous avez seulement besoin d’héberger quelques VM internes sans intégration cloud, une plateforme de virtualisation traditionnelle peut suffire. Azure Local prend de la valeur quand vous avez besoin d’un entre-deux bien précis.
| Critère | Azure Local | Azure public | Virtualisation classique |
|---|---|---|---|
| Latence | Très adaptée aux traitements proches de la source | Dépend de la qualité de la liaison réseau | Bonne sur site, mais sans intégration cloud native |
| Résidence des données | Les données restent localement | Déployées dans une région Azure | Localement aussi, mais avec une gouvernance moins unifiée |
| Connexion Internet | Peut fonctionner en mode déconnecté, avec synchronisation régulière | Connexion fortement attendue | Faible dépendance si tout reste interne |
| Gestion | Unifiée via Azure Arc et le portail Azure | Native Azure | Souvent fragmentée entre plusieurs outils |
| Cas d’usage idéal | Industrie, retail, secteur public, sites distants, environnements souverains | Nouveaux services, élasticité, SaaS, PaaS | Consolidation simple de serveurs virtuels |
À mon sens, le bon signal est simple: si votre application perd beaucoup de valeur dès qu’elle s’éloigne du lieu où les données sont produites, la solution hybride commence à devenir sérieuse. Pour comprendre pourquoi, il faut regarder l’architecture plus en détail.
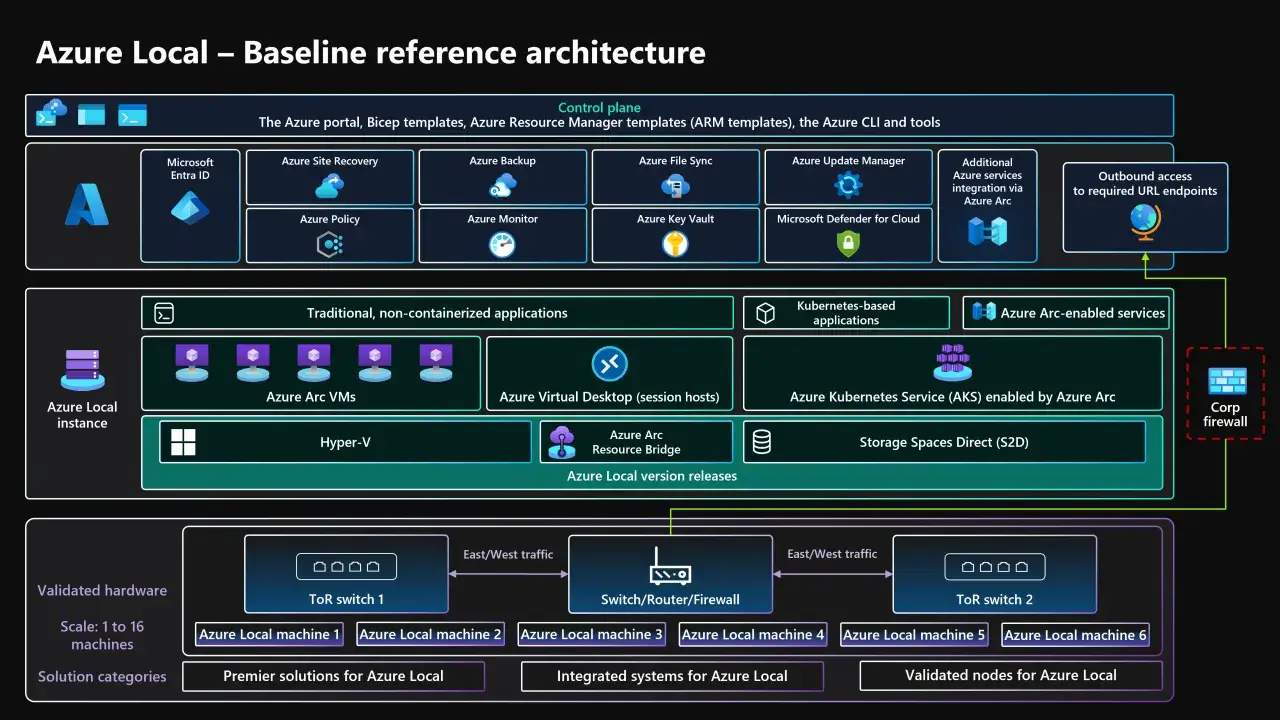
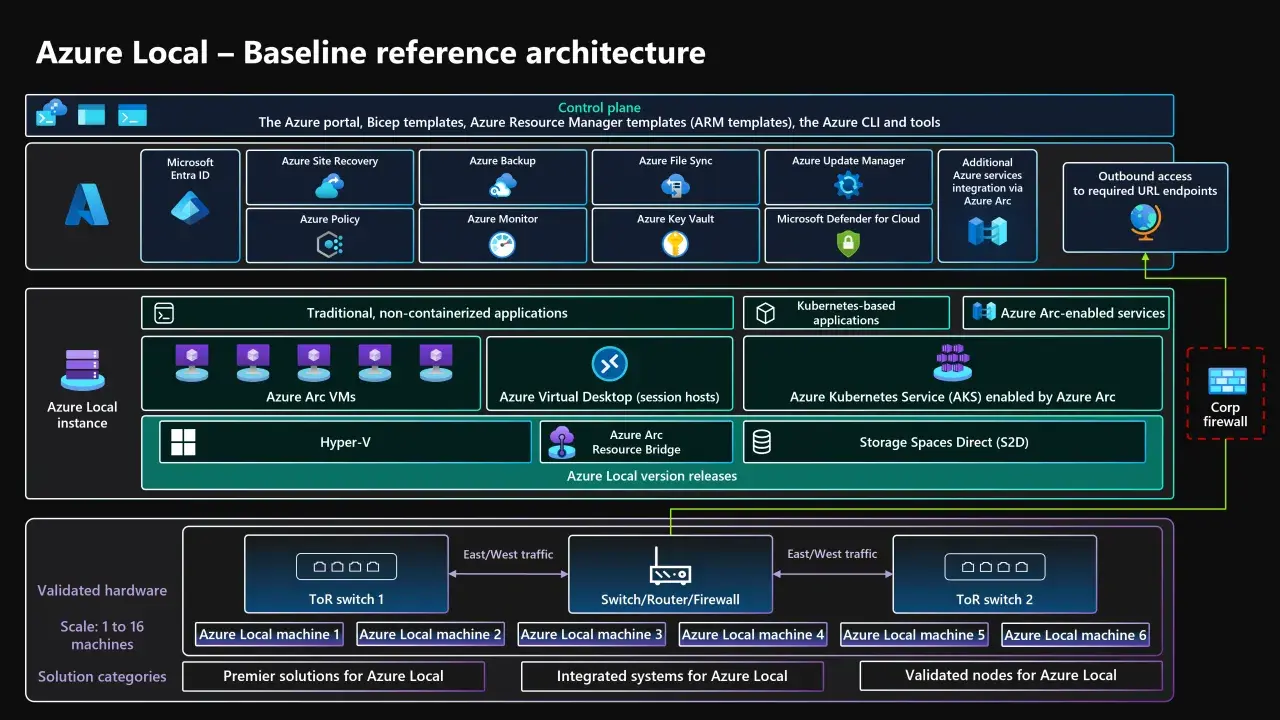
Comment l’architecture s’organise en pratique
Une instance Azure Local repose sur du matériel validé, un système d’exploitation dédié, et un ensemble de composants qui font le lien entre l’infrastructure locale et Azure. En pratique, cela combine de la virtualisation, du stockage distribué, du clustering et une couche de gestion cloud.
Les briques les plus importantes sont assez lisibles: le calcul s’appuie sur Hyper-V, le stockage distribué sur Storage Spaces Direct, et la haute disponibilité sur Windows Server Failover Clustering. Ce trio donne la base technique, mais c’est Azure Arc qui rend l’ensemble exploitable comme une extension du cloud plutôt qu’un silo local de plus.
La taille d’une instance peut aller d’une machine unique à un cluster de 16 machines physiques. C’est un point structurant, car cela permet de couvrir des scénarios très différents: un petit site périphérique, une agence régionale, ou une infrastructure plus robuste pour un datacenter de proximité.
Dans les environnements compacts, les clusters à 2 nœuds sont souvent intéressants, notamment pour des sites de bordure où l’on veut limiter les coûts sans sacrifier la continuité de service. Dès qu’on monte en taille, une topologie réseau validée devient essentielle, parce que le comportement du stockage et la résilience du cluster dépendent directement du câblage et des commutateurs.
Je trouve utile de retenir une règle simple: plus le site est petit, plus l’architecture doit être pensée pour rester sobre; plus le site est critique, plus la discipline de conception réseau et de supervision devient importante. Cette logique mène naturellement aux cas d’usage qui justifient le projet.
Les cas d’usage qui justifient vraiment le projet
Je vois la solution comme particulièrement convaincante dans quatre familles de scénarios.
- Industrie et production - Les chaînes de fabrication, les systèmes de contrôle et les environnements de qualité exigent souvent une latence très faible. Ici, traiter les données localement évite de dépendre du WAN pour des décisions temps quasi réel.
- Retail et points de vente - Dans un magasin, l’inférence locale pour la caisse, la prévention de la démarque ou certains services de vidéo-analyse a du sens. Le traitement au plus près de la donnée réduit les délais et limite les effets d’une coupure réseau.
- Secteur public et activités réglementées - Si la donnée doit rester localement maîtrisée, la question n’est pas seulement technique. Elle touche aussi à la conformité, à l’audit et à la maîtrise opérationnelle du système.
- Sites distants ou isolés - Entrepôts, stations de transport, installations énergétiques, mines, sites maritimes: dès que la connectivité est inégale, la capacité à continuer à fonctionner localement devient un vrai avantage.
Le point commun de ces cas, c’est que le cloud n’est pas rejeté. Il est simplement repositionné: la donnée et l’exécution sensible restent sur place, tandis que la supervision, la gouvernance et certains services restent reliés à Azure. Une fois ces cas identifiés, le succès dépend surtout de la manière dont on prépare le déploiement.
Déployer sans se tromper sur les prérequis
Le piège classique consiste à croire que le déploiement est surtout une affaire d’installation logicielle. En réalité, le cadrage matériel et réseau compte autant que le reste. Je conseille toujours de partir du matériel validé, puis de vérifier la topologie réseau avant même de parler du portail Azure.
- Validez le matériel dans le catalogue officiel et dimensionnez l’instance selon le nombre de nœuds, le stockage et les exigences de résilience.
- Préparez l’environnement Active Directory si votre scénario le demande, puis vérifiez les permissions de subscription et d’administration.
- Choisissez la topologie réseau adaptée: sur les déploiements à un ou deux nœuds, le mode sans switch pour le stockage peut convenir; au-delà, il faut une conception réseau commutée.
- Installez l’OS, puis enregistrez les machines avec Azure Arc pour raccorder l’infrastructure à la gouvernance Azure.
- Déployez ensuite via le portail Azure ou un modèle ARM, selon votre niveau d’automatisation et de standardisation.
Pour un pilote, Microsoft propose aussi un essai de 60 jours pour le téléchargement de l’OS, ce qui permet de valider la chaîne de déploiement avant d’engager un projet plus large. C’est une bonne approche si vous voulez tester le comportement réel du réseau, la supervision et l’intégration avec vos outils internes.
Les erreurs que je vois le plus souvent sont assez répétitives: matériel non validé, réseau sous-dimensionné, oubli des dépendances d’identité, ou manque de préparation sur la supervision. Une fois le pilote cadré, la question qui change tout est celle du coût total et des règles de facturation.
Coûts, licence et exploitation au quotidien
La facturation repose sur un modèle simple à comprendre: vous payez selon le nombre de cœurs physiques présents sur les machines, pas selon le nombre de VM créées. C’est un point important, parce que ce modèle évite les surprises liées aux pics de virtualisation, mais il impose de raisonner en capacité matérielle réelle.
En pratique, les charges Azure Local apparaissent sur votre abonnement Azure existant, et des frais supplémentaires peuvent s’ajouter si vous consommez d’autres services Azure à côté. Il n’y a pas, pour la plateforme elle-même, de licence on-premises traditionnelle à acheter comme dans certains modèles historiques, même si les VM invitées peuvent exiger leurs propres licences système.
Si vous disposez déjà de Windows Server Datacenter avec Software Assurance, Azure Hybrid Benefit peut réduire le coût global. C’est un levier souvent sous-estimé, alors qu’il peut peser fortement dans un projet où l’on exploite beaucoup de VM Windows.
Voici les leviers qui pèsent le plus sur le coût réel:
- le nombre de cœurs physiques à facturer;
- le type de matériel validé choisi;
- les licences nécessaires pour les machines invitées;
- les services Azure additionnels consommés;
- les coûts d’exploitation liés à la supervision, aux mises à jour et au support.
Un autre détail mérite d’être anticipé: la plateforme doit se connecter à Azure au moins une fois tous les 30 jours pour la facturation, et l’absence de synchronisation prolongée n’est pas anodine. Autrement dit, le modèle est souple, mais il n’est pas totalement découplé du cloud. C’est précisément ce qui amène aux limites à connaître avant de trancher.
Les limites à connaître avant de trancher
Le premier frein, c’est le faux sentiment de simplicité. Azure Local n’est pas un simple hyperviseur avec une couche marketing au-dessus. C’est une infrastructure distribuée qui demande une vraie rigueur d’intégration, surtout sur le réseau, l’identité, le stockage et le cycle de vie des mises à jour.
Le deuxième frein, c’est le matériel. Tout serveur ne convient pas. Si vous partez sur une base non validée, vous prenez un risque technique et opérationnel qui peut vite annuler le bénéfice du projet. Je préfère toujours voir un hardware proprement sélectionné plutôt qu’une tentative de réemploi trop optimiste.
Le troisième frein, c’est la connectivité. La solution peut fonctionner en mode déconnecté, mais elle n’efface pas la nécessité de synchroniser régulièrement l’environnement avec Azure. Si votre site est coupé du réseau pendant des périodes longues, il faut accepter qu’un fonctionnement hybride implique aussi des règles de gestion précises.
Enfin, il faut être honnête sur le positionnement: si votre besoin se limite à quelques VM locales sans exigence cloud, la plateforme peut être trop lourde pour ce qu’elle apporte. Elle prend tout son sens quand vous cherchez à combiner exécution locale, gouvernance Azure et continuité de service. Avant de lancer une mise en production, je préfère donc vérifier quelques points très concrets.
Ce que je vérifierais avant de lancer un pilote
Avant de signer, je regarde toujours cinq questions simples. La première: quelle application doit réellement rester locale, et pour quelle raison mesurable? La deuxième: quelle latence ou quelle indisponibilité maximale est acceptable? La troisième: le matériel et la topologie réseau sont-ils déjà compatibles avec la plateforme, ou faudra-t-il tout refaire?
Je vérifie aussi qui exploitera la solution au quotidien. Une infrastructure hybride réussie n’est pas seulement un achat, c’est un contrat implicite sur les compétences internes: supervision, mises à jour, sécurité, gestion des identités et remédiation en cas d’incident. Si l’équipe n’a pas le temps ou les habitudes nécessaires, la belle promesse hybride se transforme vite en dette opérationnelle.
Mon approche reste pragmatique: je conseille de commencer avec un seul workload critique mais mesurable, de suivre le comportement sur 30 à 60 jours, puis d’évaluer les gains réels en latence, en continuité et en charge d’exploitation. Si les résultats sont nets, la plateforme a sa place. Sinon, il vaut mieux conserver une architecture plus simple et investir dans ce qui résout vraiment le problème.