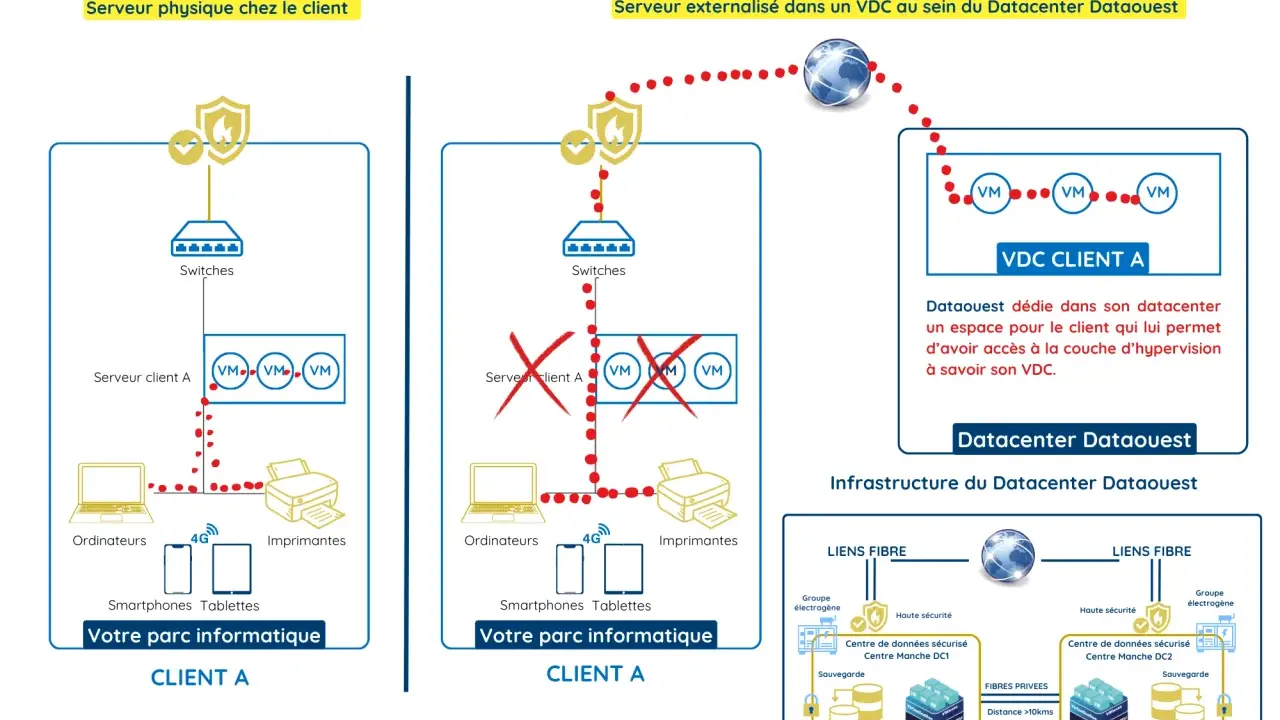
Un data serveur n’est pas seulement un boîtier qui stocke des fichiers : c’est la brique qui héberge, sert et protège les données qu’une application doit lire vite, sans interruption et avec un niveau de sécurité cohérent avec son usage. Dans un contexte cloud et infrastructure, la vraie question n’est pas seulement où résident les données, mais comment elles sont administrées, répliquées et surveillées au quotidien. Je vais donc aller à l’essentiel : les modèles d’hébergement, les gestes d’exploitation, les points de sécurité et les critères concrets qui évitent les mauvaises décisions.
Les points clés à garder en tête avant de choisir votre architecture
- Un serveur de données regroupe le calcul, le stockage, les accès, les logs et souvent la réplication, pas seulement la base elle-même.
- Le cloud apporte surtout de la souplesse et des services managés, mais il ne réduit pas automatiquement la complexité d’exploitation.
- Le bon modèle dépend du niveau de contrôle attendu, de la charge, des compétences internes et des contraintes de conformité.
- Les erreurs les plus coûteuses restent classiques : sauvegarde non testée, droits trop larges, coûts de sortie ignorés et monitoring incomplet.
- En France, la sécurité et le RGPD imposent une approche structurée, surtout pour les données sensibles ou stratégiques.
Ce qu’on met vraiment derrière un serveur de données
Je parle ici d’un ensemble, pas d’une seule machine. Dans la pratique, un serveur de données rassemble le calcul, le stockage, les règles d’accès, la journalisation et souvent une couche de réplication qui protège le service si un nœud tombe. Dans le cloud, cette fonction peut vivre sur une machine virtuelle, un serveur bare metal, un service managé de base de données ou un cluster réparti sur plusieurs zones.
La confusion la plus fréquente consiste à réduire le sujet à la base de données elle-même. Or, ce qui compte pour l’utilisateur final, c’est la chaîne complète : lecture rapide, cohérence des écritures, sauvegardes, restauration possible, supervision et capacité à encaisser une montée de charge. J’aime résumer cela ainsi : une bonne donnée n’a de valeur que si son chemin d’accès est fiable.
Cette lecture aide à éviter un piège classique : choisir une technologie impressionnante sur le papier, puis découvrir qu’elle est trop lourde à maintenir pour l’équipe disponible. C’est justement ce qui mène au choix du modèle d’hébergement.
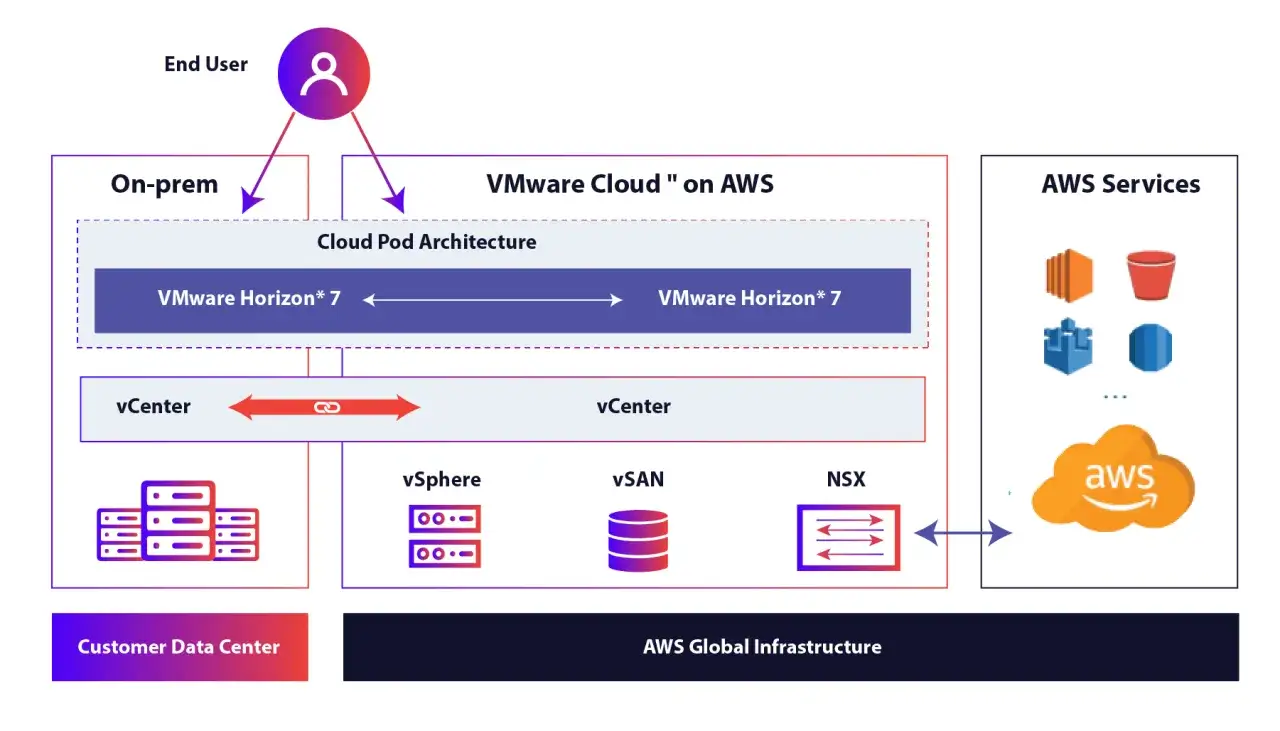
Les modèles d’hébergement qui comptent en pratique
Quand j’évalue une architecture, je ne compare pas seulement des prix. Je compare surtout le niveau de contrôle, la vitesse de déploiement et le coût réel d’exploitation. Le bon modèle n’est pas celui qui paraît le plus moderne, mais celui qui correspond à la charge, aux compétences internes et au niveau de criticité.| Modèle | Ce qu’il apporte | Limites | Quand je le conseille |
|---|---|---|---|
| Cloud public | Déploiement rapide, élasticité, nombreux services managés, paiement à l’usage | Facture variable, coûts de sortie potentiels, dépendance au fournisseur | Charges variables, projets qui doivent aller vite, équipes qui veulent réduire l’exploitation lourde |
| Cloud privé | Contrôle fin, isolation, meilleure maîtrise de l’environnement | Gestion plus lourde, investissement et maintenance plus élevés | Données sensibles, environnements très encadrés, exigences fortes de gouvernance |
| Hybride | Transition progressive, répartition des usages, proximité de certaines données | Intégration plus complexe, supervision à unifier | Migrations par étapes, coexistence avec l’existant, contraintes de latence ou de localisation |
| Bare metal | Performances stables, pas d’hyperviseur, très bon contrôle des ressources | Moins de flexibilité, capacité à planifier plus strictement | Charges I/O intensives, licences spécifiques, besoins de performance très prévisibles |
| DBaaS | Base de données managée, sauvegardes et mises à jour souvent simplifiées | Moins de liberté bas niveau, contraintes propres au service | Équipes réduites, besoin de fiabilité opérationnelle, mise sur le marché accélérée |
Ce que la gestion quotidienne change vraiment
Le premier gain d’un environnement cloud bien tenu, ce n’est pas la vitesse de création d’une instance. C’est la capacité à faire de l’exploitation un processus répétable. Je regarde toujours les mêmes quatre axes : supervision, sauvegarde, mises à jour et capacité.
- Supervision : CPU, mémoire, IOPS, latence, erreurs applicatives et saturation réseau. Sans ces indicateurs, on pilote à l’aveugle.
- Sauvegarde : la règle 3-2-1 reste une base solide, avec trois copies, sur deux supports, dont une hors site. Une sauvegarde non restaurée n’est pas une preuve de reprise.
- Mises à jour : je préfère des fenêtres courtes et régulières à de grandes opérations rares. Les correctifs de sécurité accumulés finissent presque toujours par coûter plus cher que le temps qu’on voulait économiser.
- Capacité : observez les tendances sur 30 à 90 jours, pas seulement le pic du jour. Beaucoup d’équipes achètent trop tôt de la marge… ou, à l’inverse, la découvrent trop tard.
Sécurité, RGPD et continuité de service
Sur un serveur de données, la sécurité n’est pas une couche ajoutée après coup. Elle doit être pensée dès le départ, parce qu’un seul compte trop large ou un chiffrement mal géré suffit à fragiliser l’ensemble. La CNIL rappelle que l’obligation de sécurité prévue par l’article 32 du RGPD impose des mesures adaptées aux risques ; en clair, il faut les choisir en fonction de la sensibilité réelle des données, pas d’une checklist théorique.
- Chiffrement : je le veux au repos et en transit, avec une gestion des clés séparée quand c’est possible.
- Contrôle d’accès : le principe du moindre privilège n’est pas une idée abstraite ; il limite les dégâts lorsqu’un compte est compromis.
- Authentification multifacteur : indispensable pour les comptes d’administration et les accès distants.
- Journalisation : les logs doivent couvrir les accès, les modifications et les échecs de connexion, avec une rétention adaptée.
- Segmentation : isolez les environnements de production, de test et d’administration pour éviter les traversées inutiles.
Pour la continuité de service, je distingue toujours deux notions : RTO, le temps maximal acceptable pour remettre le service en ligne, et RPO, la perte de données maximale tolérée. Un objectif de disponibilité de 99,9 % correspond à environ 8 h 46 min d’arrêt par an ; 99,99 % tombe à un peu plus de 52 minutes. Ce simple calcul aide à remettre les SLA dans le bon ordre de grandeur et à décider si une seule zone suffit ou si une redondance multi-zone est réellement nécessaire.
En France, pour les environnements les plus sensibles, je regarde aussi des référentiels de confiance comme SecNumCloud quand la maîtrise des accès et la souveraineté deviennent prioritaires. Cette couche de protection n’est pas un luxe : elle conditionne directement le choix du modèle d’hébergement.
Comment choisir entre cloud public, privé et hybride
Je pars rarement d’une préférence de principe. Je pars d’un usage. Un service très variable, lancé vite et mis à jour souvent, n’appelle pas la même réponse qu’un système stable, sensible ou fortement contraint par la latence. C’est là qu’il faut trancher, sans fantasmer le modèle parfait.
- Cloud public : idéal si la charge varie, si l’équipe veut aller vite et si des services managés réduisent la charge d’exploitation. Je le vois souvent pour des applications web, des environnements de test ou des produits qui changent vite.
- Cloud privé : pertinent quand le contrôle, l’isolation ou certaines contraintes de résidence des données priment sur la souplesse. Il reste utile pour des systèmes hérités ou des secteurs très encadrés.
- Hybride : intéressant pour migrer par étapes, garder une partie des données à proximité ou absorber un pic sans refaire tout l’existant. Sa contrepartie, c’est la complexité d’intégration.
- DBaaS : je le recommande quand l’équipe veut se concentrer sur le métier plutôt que sur la maintenance du moteur. On paie moins en liberté technique, mais on gagne souvent en vitesse et en fiabilité opérationnelle.
- Bare metal : à envisager pour des charges à I/O intensif, des licences particulières ou des exigences de performance très stables. Là, le compromis principal est la flexibilité.
Pour des utilisateurs en France, je regarde aussi la proximité de la région cloud, car elle joue sur la latence et parfois sur la gestion des transferts. Dans les faits, le bon choix dépend surtout du coût total sur 12 à 36 mois, des compétences disponibles et du niveau de risque acceptable. Cette logique de décision éclaire aussi les erreurs les plus fréquentes.
Les erreurs qui reviennent le plus souvent
La plupart des incidents coûteux viennent de décisions simples, pas de technologies exotiques. Quand j’audite une infrastructure de données, je retrouve presque toujours les mêmes angles morts.
- Confondre réplication et sauvegarde : la réplication protège contre la panne, pas contre la suppression accidentelle ou le chiffrement malveillant.
- Oublier les coûts de sortie : le stockage attire l’attention, mais les transferts réseau et la sortie de données peuvent peser lourd dans la facture.
- Laisser des droits trop larges : un compte d’administration partagé ou non revu régulièrement est une faiblesse majeure.
- Ne jamais tester la restauration : tant que la reprise n’a pas été simulée, on ne connaît ni le délai réel ni les points de rupture.
- Surprovisionner “au cas où” : on paie alors pour de la marge inactive, ce qui finit par masquer le vrai besoin.
- Mélanger production, test et archivage : ce mélange complique les droits, la performance et la conformité.
Je préfère prévenir une fois de trop : un excellent outil mal gouverné produit souvent un résultat moins bon qu’un outil plus simple mais bien opéré. C’est exactement pour cela qu’il faut verrouiller les étapes de préparation avant la migration.
Ce qu’il faut verrouiller avant de migrer ou de moderniser
Avant de déplacer un serveur de données vers le cloud, je verrouille toujours les mêmes points :
- Classer les données selon leur sensibilité et leur criticité.
- Fixer un RTO et un RPO réalistes, puis les confronter aux coûts.
- Choisir clairement ce qui restera managé, auto-géré ou hybridé.
- Documenter les accès, les logs, les responsabilités et les procédures de restauration.
- Tester un basculement et une restauration sur un périmètre pilote avant le passage à l’échelle.
- Prévoir un scénario de sortie pour ne pas dépendre d’un seul fournisseur ou d’un seul format.
Quand ces six points sont clairs, la décision devient beaucoup plus rationnelle : on ne choisit plus une promesse de performance, on choisit une infrastructure capable de tenir la charge, la sécurité et le budget sur la durée. C’est, à mes yeux, la vraie maturité d’un environnement de données.