Le cloud a changé la manière dont on héberge une application, un espace de travail ou une base de données, mais son fonctionnement reste souvent mal compris. Le fonctionnement cloud repose sur une idée simple: répartir les ressources sur plusieurs serveurs, les rendre disponibles à la demande et automatiser au maximum la mise à l’échelle, la sécurité et la résilience. Je vais décortiquer ici ce qu’il y a derrière l’écran, comment une requête circule, ce qui distingue IaaS, PaaS et SaaS, puis les points qui font vraiment la différence au moment d’exploiter ou de migrer une infrastructure.
L’infrastructure cloud repose sur des ressources mutualisées, automatisées et redondées
- Le fournisseur opère les datacenters, le réseau physique, la virtualisation et une partie importante de la sécurité.
- L’utilisateur consomme des ressources à la demande: calcul, stockage, réseau, bases de données ou fonctions managées.
- Une requête passe par plusieurs étapes: DNS, authentification, équilibrage de charge, traitement applicatif et écriture dans le stockage.
- La scalabilité, la redondance et la sauvegarde évitent qu’une panne locale bloque tout le service.
- Le vrai sujet n’est pas seulement la technologie, mais aussi la gouvernance des accès, des coûts et des dépendances.
Le cloud ne tient pas sur une seule machine
Je préfère penser le cloud comme une plateforme distribuée plutôt que comme un serveur distant. Les guides AWS et Microsoft le décrivent d’ailleurs comme un ensemble de ressources de calcul, de stockage et de réseau installées dans des datacenters, puis exposées sous forme de services. En pratique, cela veut dire qu’une application ne s’appuie pas sur un seul boîtier physique, mais sur plusieurs couches qui coopèrent: le matériel, la virtualisation, le réseau, les outils d’orchestration et les services consommés par l’équipe.
Cette organisation change tout. Au lieu d’acheter une machine, de l’installer, de la maintenir et d’anticiper sa capacité pour les trois prochaines années, on consomme une capacité variable, souvent en quelques clics ou via une API. Le cloud est donc moins un produit qu’un mode d’exploitation. La même logique sert à héberger un site web, une application métier, des fichiers collaboratifs ou un environnement de test. Pour comprendre ce modèle, il faut regarder les briques qui le composent vraiment.
La suite montre précisément comment ces briques s’assemblent et pourquoi elles rendent possible la flexibilité que les équipes recherchent.
Les briques techniques qui font tourner l’ensemble
Une infrastructure cloud repose sur quatre fondations simples à nommer, mais plus riches qu’elles n’en ont l’air: le calcul, le stockage, le réseau et l’orchestration. Je les distingue toujours, parce que les problèmes qu’elles résolvent ne sont pas les mêmes.
Le calcul
Le calcul correspond à la puissance de traitement. Dans le cloud, il prend souvent la forme de machines virtuelles ou d’instances, parfois de conteneurs. Une machine virtuelle isole un système d’exploitation et ses applications au-dessus du matériel physique grâce à un hyperviseur. Un conteneur, lui, partage davantage de ressources avec l’hôte et lance une application dans un environnement plus léger. Le premier sert bien les besoins classiques et les environnements très compatibles; le second simplifie le déploiement rapide et la portabilité.
Le stockage
Le stockage n’est pas un simple disque éloigné. Il existe plusieurs formes, et leur usage n’est pas interchangeable:
- Le stockage bloc sert aux bases de données et aux charges qui demandent des accès rapides et structurés.
- Le stockage fichier convient aux partages de documents et aux environnements qui ressemblent à un serveur de fichiers classique.
- Le stockage objet est conçu pour conserver de gros volumes de fichiers, d’archives, d’images ou de sauvegardes avec une excellente évolutivité.
Dans une équipe bureautique, c’est souvent le stockage objet qui absorbe les sauvegardes et les archives, tandis que les dossiers de travail courant restent sur un espace fichier plus familier. Cette distinction évite beaucoup de confusion au moment de dimensionner l’infrastructure.
Le réseau
Le réseau relie tout le reste. Sans lui, le cloud n’existe pas. Les composants courants sont le load balancer qui répartit les requêtes, les pare-feu réseau, les sous-réseaux isolés, les VPN, les liaisons privées et parfois un CDN, c’est-à-dire un réseau de diffusion de contenu qui rapproche les données statiques de l’utilisateur. C’est souvent là que se joue la qualité perçue: deux applications identiques peuvent donner une expérience très différente selon la latence, la bande passante et les réglages de routage.
Lire aussi : Data center c'est quoi - Fonctionnement, modèles et critères de choix
L’orchestration
L’orchestration est la couche qui automatise les actions répétitives: créer une machine, lancer un conteneur, ouvrir le bon port, répliquer un volume, déclencher un autoscaling, redémarrer un service sain après une panne. C’est aussi elle qui permet l’infrastructure as code, c’est-à-dire la description de l’environnement sous forme de fichiers versionnés. En pratique, cela réduit les écarts entre l’environnement de test et la production, ce qui est un vrai gain de fiabilité.
Une fois ces briques posées, il devient beaucoup plus simple de suivre le trajet d’une requête, du navigateur jusqu’à la base de données.
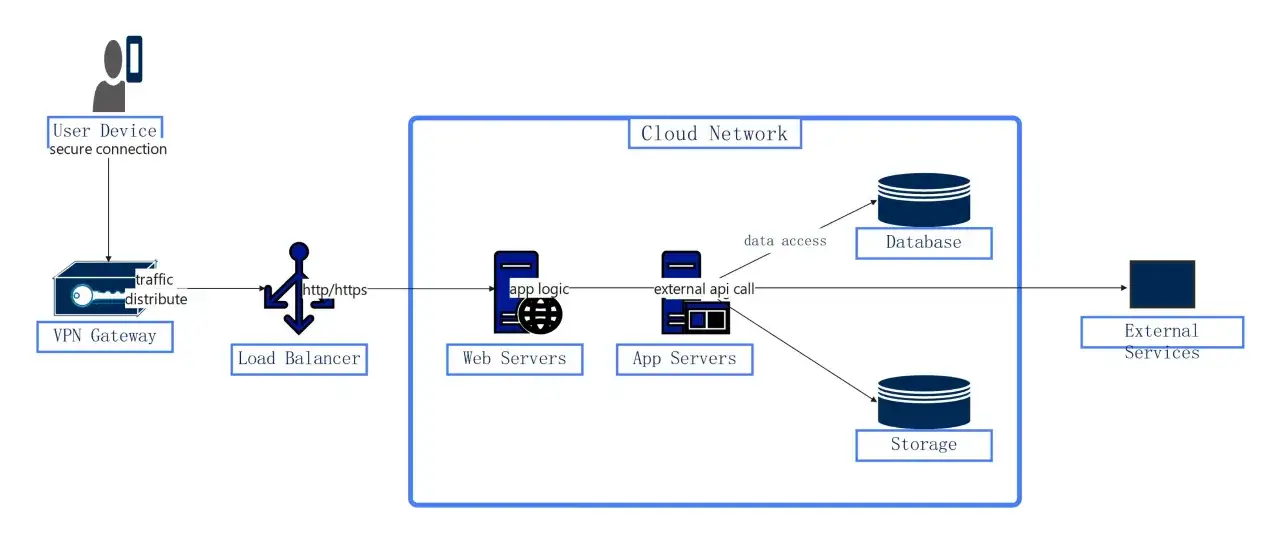
Du clic de l’utilisateur à la réponse de l’application
Quand un utilisateur ouvre une application cloud, plusieurs mécanismes se déclenchent en quelques millisecondes ou quelques secondes. Le parcours est plus lisible qu’il n’y paraît:
- Le nom de domaine est résolu par le DNS, qui indique où joindre le service.
- La connexion est sécurisée par TLS, afin de chiffrer les échanges entre le client et la plateforme.
- Un load balancer oriente la requête vers une instance disponible et en bonne santé.
- L’application exécute la logique métier, souvent dans un conteneur ou une machine virtuelle.
- Si elle doit lire ou écrire des données, elle interroge une base, un cache ou un stockage objet.
- Les journaux, métriques et traces enregistrent l’événement pour surveiller la qualité du service.
Ce chemin explique pourquoi le cloud peut sembler “transparent” côté utilisateur tout en restant très structuré côté exploitation. La vitesse d’affichage ne dépend pas uniquement de la puissance serveur; elle dépend aussi du cache, du routage, des dépendances externes et de la capacité du backend à répondre sans file d’attente inutile. Dans une application bien conçue, une partie des contenus statiques passe par un CDN, ce qui évite de faire voyager les mêmes fichiers à travers tout le réseau à chaque consultation.
Quand ce trajet est maîtrisé, on peut aller plus loin: faire absorber les pics de trafic sans casser l’expérience et tenir une panne locale sans arrêter le service.
L’élasticité et la redondance changent la façon d’exploiter un service
Le grand intérêt du cloud n’est pas seulement d’héberger une application, mais de lui donner une élasticité que l’on obtient difficilement avec un serveur unique. L’élasticité consiste à ajouter ou retirer de la capacité en fonction de la demande. Une campagne marketing, une clôture comptable, un pic saisonnier ou un usage imprévu peuvent ainsi être absorbés sans immobiliser une infrastructure surdimensionnée toute l’année.
La redondance va dans le même sens: on duplique les composants critiques pour éviter qu’un incident isolé coupe tout le service. On parle souvent de plusieurs zones de disponibilité, de réplication des données, de bascule automatique et de sauvegardes hors ligne ou hors site. Le point important est simple: le cloud ne supprime pas la panne, il la contient. Une bonne architecture limite le rayon d’impact et accélère le retour à la normale.Dans les projets sérieux, je regarde aussi deux indicateurs souvent oubliés: le RPO, qui mesure la perte de données acceptable, et le RTO, qui mesure le temps maximal de reprise. Une plateforme peut être très robuste tout en étant mal alignée sur ces objectifs. Une base métier critique n’a pas les mêmes exigences qu’un partage de fichiers interne ou qu’un portail documentaire.
Cette logique de disponibilité prépare une autre question, plus concrète encore: qui gère quoi entre le fournisseur et l’équipe cliente?
IaaS, PaaS et SaaS ne demandent pas le même niveau de pilotage
Le modèle de service change la frontière de responsabilité. C’est souvent là que les équipes se trompent, en imaginant que “passer au cloud” efface la complexité. En réalité, elle se déplace.
| Modèle | Ce que gère le fournisseur | Ce que vous gérez | Usage typique |
|---|---|---|---|
| IaaS | Datacenters, matériel, réseau, virtualisation | Système d’exploitation, middleware, application, données | Migration d’un environnement existant, contrôle fin de la pile |
| PaaS | Infrastructure, OS, runtime, mise à l’échelle | Code applicatif, configuration métier, données | Développement plus rapide, moins d’administration |
| SaaS | Presque toute la pile technique | Utilisateurs, droits, paramétrage, qualité des données | Messagerie, CRM, bureautique, collaboration |
Le serverless pousse encore plus loin cette logique: le fournisseur exécute les fonctions à la demande, et l’équipe se concentre surtout sur le code et les événements déclencheurs. C’est très efficace pour des traitements ponctuels, mais ce n’est pas une baguette magique. Dès qu’il faut un contrôle précis de la pile, des dépendances réseau ou du coût à grande échelle, il faut revenir à une lecture plus fine de l’architecture.
Le bon choix n’est donc pas “le cloud le plus moderne”, mais le modèle qui correspond au niveau de contrôle et de charge opérationnelle que l’on veut réellement assumer.
Sécurité, conformité et coûts suivent la même logique de partage
Les guides AWS et Microsoft rappellent tous deux une idée centrale: le fournisseur protège l’infrastructure, mais le client reste responsable des identités, des configurations, des données et d’une partie des réglages de sécurité. C’est ce qu’on appelle la responsabilité partagée. En pratique, cela signifie que la sécurité ne se résume pas à choisir un grand nom de cloud; elle dépend surtout de la manière dont on configure ce cloud.
Les points à surveiller en priorité sont connus, mais ils restent les plus souvent négligés:
- IAM et MFA pour limiter les droits et exiger une authentification forte.
- Chiffrement des données en transit et au repos.
- Journalisation et surveillance des événements sensibles.
- Segmentation réseau pour éviter qu’un service exposé n’ouvre tout le reste.
- Sauvegardes testées, pas seulement planifiées.
Sur le plan financier, le piège classique est de croire que la facture ne dépend que du nombre de serveurs. En réalité, les coûts invisibles s’accumulent vite: stockage qui grossit sans nettoyage, trafic sortant, journaux trop verbeux, environnements de test oubliés, services managés surdimensionnés, licences et support. C’est là que le FinOps devient utile: cette pratique relie la dépense cloud à un usage métier concret, au lieu de laisser la facture dériver sans arbitrage.
Et parce que la technique ne suffit jamais à elle seule, il reste une dernière étape avant toute migration sérieuse: vérifier si le projet est vraiment prêt à changer d’infrastructure.
Ce que je vérifie avant de migrer une application
Avant de déplacer quoi que ce soit, je passe toujours par une grille simple. Elle évite les migrations brillantes sur le papier et décevantes en production.
- La charge réelle de l’application: régulière, cyclique ou imprévisible.
- La sensibilité des données: contraintes internes, sectorielles ou de localisation.
- La compatibilité technique: dépendances, versions logicielles, besoins réseau.
- Le niveau de compétence de l’équipe: exploitation, supervision, sécurité, sauvegarde.
- Le coût complet: infrastructure, trafic, licences, support, exploitation.
- La réversibilité: capacité à revenir en arrière ou à changer de fournisseur sans blocage.
Si l’objectif est de réduire la charge d’exploitation sans compliquer la vie des équipes, je commence rarement par le cœur du SI. Je choisis plutôt un service bien borné, je mesure la latence, le coût et la maintenabilité pendant quelques semaines, puis j’élargis seulement si les chiffres sont bons. C’est souvent la manière la plus saine d’aborder une transformation cloud: moins spectaculaire, mais beaucoup plus fiable.
Au fond, le cloud fonctionne bien quand il simplifie une contrainte précise sans créer de dette cachée ailleurs. Si vous retenez une seule idée, gardez celle-ci: la valeur ne vient pas seulement de l’hébergement à distance, mais de la capacité à combiner automatisation, redondance, sécurité et pilotage économique dans une même architecture.