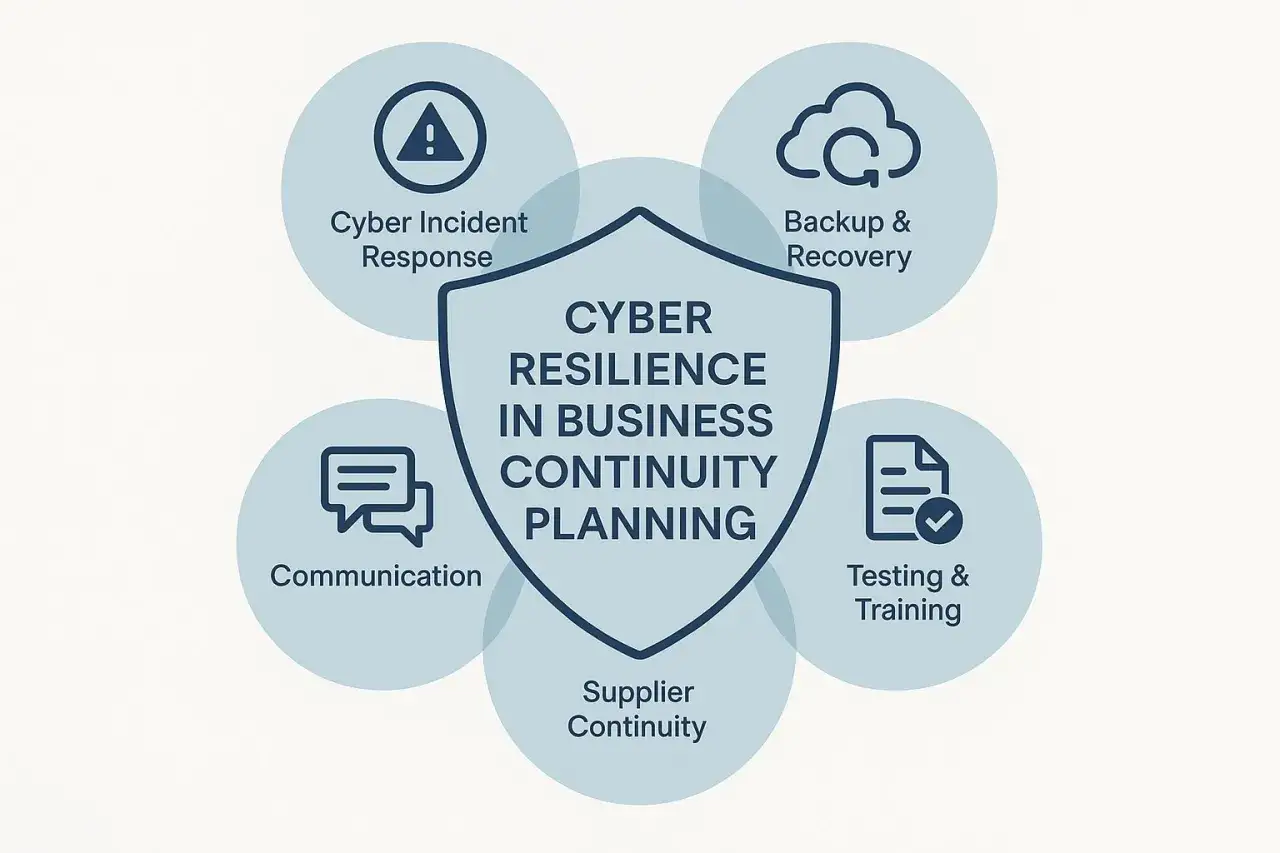
Les points qui comptent pour tenir après une attaque
- La résilience vise la continuité des activités essentielles, pas l’absence totale d’incident.
- Il faut d’abord cartographier les services critiques, leurs dépendances et le niveau de dégradation acceptable.
- Un PCA et un PRA ne valent que s’ils s’appuient sur des sauvegardes isolées, des restaurations testées et des rôles clairs.
- MFA, segmentation réseau, EDR et gestion stricte des privilèges réduisent fortement le rayon d’impact d’une compromission.
- La première journée de crise se joue sur la décision, la communication et la capacité à préserver les preuves.
- En France, le cadre porté par l’ANSSI et NIS2 pousse à formaliser ce travail au lieu de le laisser à l’improvisation.
La résilience cyber ne consiste pas seulement à éviter l’attaque
Je préfère une définition très simple : une organisation résiliente est une organisation qui continue de fonctionner, même quand une partie de son système d’information tombe. Selon l’ANSSI, la logique de résilience vise justement le maintien des activités essentielles avec une dégradation tolérable, puis une reprise progressive vers le nominal.
Cette nuance change tout. La prévention cherche à empêcher l’incident, la détection cherche à le voir, la réponse cherche à le contenir, et la résilience cherche à absorber le choc sans perdre l’activité. Si l’on mélange ces quatre sujets, on finit souvent avec une belle politique de sécurité et zéro capacité réelle de reprise.
Concrètement, je raisonne toujours en trois verbes :
- Continuer : garder en vie les processus qui font tourner le métier, même en mode dégradé.
- Récupérer : restaurer les systèmes et les données sans réintroduire l’attaque.
- Apprendre : corriger ce que l’incident a révélé sur les dépendances, les délais et les angles morts.
Cette vision est plus exigeante qu’un simple durcissement technique, mais elle est aussi plus réaliste. Une fois ce cadre posé, la vraie question devient très concrète : quels services doivent absolument survivre en premier ?
Identifier les services qui doivent survivre en premier
La plupart des plans échouent parce qu’ils partent des outils au lieu de partir du métier. Je commence toujours par identifier les processus qui créent du chiffre d’affaires, assurent une obligation légale ou évitent un arrêt opérationnel immédiat. Ensuite seulement, je remonte vers les applications, les identités, les données et les prestataires dont ils dépendent.Il faut aussi fixer deux repères très pratiques : le RTO (Recovery Time Objective), c’est-à-dire le délai maximal d’interruption acceptable, et le RPO (Recovery Point Objective), c’est-à-dire la quantité de données que l’on accepte de perdre. Sans ces deux valeurs, un plan de reprise reste flou.
| Service critique | Dépendances fréquentes | Mode dégradé possible | Ce que je vérifierais |
|---|---|---|---|
| Messagerie et collaboration | Annuaire, MFA, DNS, prestataire cloud | Canal de secours, téléphone, messagerie alternative | Accès de secours et procédure de bascule |
| ERP, facturation, stock | Base de données, comptes à privilèges, réseau interne | Saisie manuelle temporaire, traitement par lots | RTO réaliste et priorité de restauration |
| Partage documentaire | Stockage, droits d’accès, classification des fichiers | Répertoire restreint, copie de travail locale | Quels documents doivent rester disponibles en premier |
| Identité et accès | Annuaire, fédération, console cloud, coffre de secrets | Comptes d’urgence hors annuaire principal | Capacité à reprendre la main sans se verrouiller soi-même |
Ce travail est souvent révélateur : on découvre qu’un outil jugé “secondaire” est en réalité le point d’entrée de plusieurs chaînes opérationnelles. Une fois cette hiérarchie claire, il devient possible de la traduire dans un PCA et un PRA qui tiennent réellement la route.
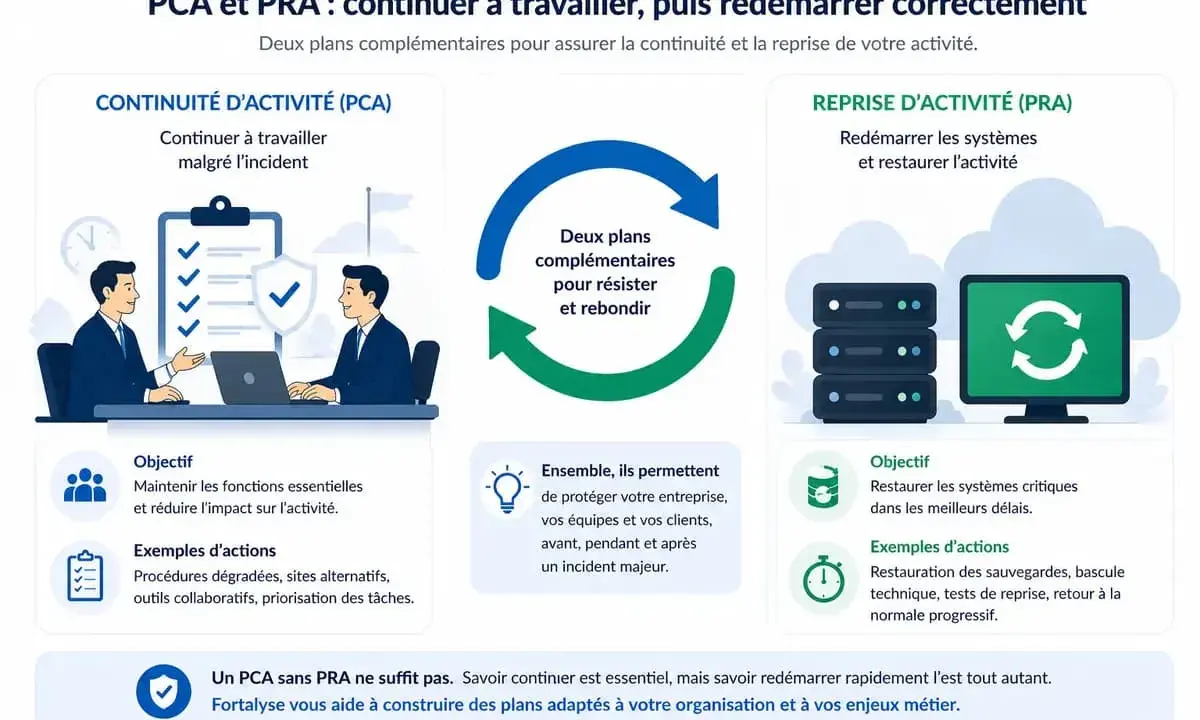
Construire un PCA et un PRA qui tiennent vraiment
Le PCA, ou plan de continuité d’activité, décrit comment l’entreprise continue à servir ses fonctions essentielles pendant la crise. Le PRA, ou plan de reprise d’activité, décrit comment elle revient progressivement à la normale après l’incident. Les deux sont liés, mais ils ne jouent pas le même rôle.
| Point de comparaison | PCA | PRA |
|---|---|---|
| Objectif | Maintenir le service en mode dégradé | Restaurer l’environnement et revenir au nominal |
| Moment d’application | Pendant l’incident | Après stabilisation et éradication de la menace |
| Contenu | Procédures de repli, contacts, circuits de validation, priorités métiers | Ordre de restauration, dépendances techniques, validation des données, tests de retour |
| Erreur fréquente | Prévoir une belle théorie sans solution de secours | Restaurer trop vite sans vérifier la persistance de l’attaque |
Le point le plus sous-estimé reste la sauvegarde. Je considère qu’une sauvegarde utile doit être séparée, testée et exploitable. En pratique, cela veut dire au moins une copie hors ligne ou immuable, des comptes d’administration distincts de ceux de production, et des restaurations réellement testées sur des jeux de données représentatifs.
La règle 3-2-1 reste un bon socle : trois copies des données, sur deux supports différents, dont une copie hors site. Mais en 2026, je recommande presque toujours d’ajouter une copie immuable ou déconnectée, parce que les attaquants ciblent désormais aussi les sauvegardes. Sans test de restauration, une sauvegarde n’est qu’une promesse.Je conseille aussi de documenter les éléments que beaucoup de plans oublient : les licences nécessaires pour redémarrer certains services, les accès aux consoles cloud, les coordonnées des prestataires, les images système de référence, les dépendances DNS et les responsabilités de validation métier. C’est ce niveau de détail qui fait la différence au moment où l’on perd le luxe de l’improvisation.
Une fois ce socle posé, il faut encore réduire la taille du dommage possible avant même que la crise n’éclate.
Les mesures techniques qui réduisent le rayon d’impact
Une bonne résilience ne repose pas sur un seul produit miracle. Elle repose sur une série de contrôles simples, bien combinés, qui empêchent une compromission de se transformer en arrêt total.
- MFA : l’authentification multifacteur ajoute une seconde preuve d’identité, ce qui bloque une grande partie des prises de compte simples, surtout sur la messagerie, le VPN et les consoles cloud.
- Segmentation réseau : elle sépare les zones critiques pour qu’un poste infecté ne puisse pas atteindre tout le reste en quelques minutes.
- PAM : le Privileged Access Management contrôle les comptes à privilèges, c’est-à-dire les accès capables de tout modifier ou tout effacer.
- EDR : un outil de Endpoint Detection and Response surveille les postes et serveurs pour détecter des comportements suspects et contenir plus vite un incident.
- Journalisation centralisée : elle conserve les traces utiles à l’enquête et à la chronologie de crise, au lieu de les laisser dispersées sur des machines compromises.
- Gestion rigoureuse des correctifs : elle réduit les portes d’entrée les plus courantes, surtout sur les services exposés et les systèmes à forte visibilité.
Je vois trop d’organisations se concentrer sur la défense périmétrique alors que le vrai point de rupture est souvent l’identité. Si un attaquant prend la main sur les comptes administrateurs, le problème n’est plus seulement technique : il devient organisationnel, parce que toutes les dépendances se mettent à tomber les unes après les autres.
Il faut aussi penser aux prestataires et aux SaaS. Une chaîne de résilience n’est pas plus solide que son maillon le plus fragile : hébergeur, annuaire, sauvegarde, supervision, outil de support, messagerie, tout compte. C’est précisément ce qui mène à la gestion de crise, là où les premières heures deviennent décisives.
La première journée après un incident décide souvent du reste
Quand un incident sérieux démarre, je préfère une séquence courte, claire et répétée plutôt qu’un long document théorique. L’objectif n’est pas de tout résoudre en quelques minutes ; il est d’éviter les décisions irréversibles prises trop tôt.
| Temps | Priorité | Action concrète |
|---|---|---|
| 0 à 15 minutes | Confinement | Isoler les systèmes touchés, protéger les comptes sensibles, couper les accès suspects |
| 1 heure | Coordination | Activer la cellule de crise, nommer un décideur, fixer un canal unique de communication |
| 24 heures | Évaluation | Qualifier l’ampleur, l’impact métier, les données exposées et les dépendances à restaurer en premier |
| 72 heures | Reprise contrôlée | Restaurer par priorité, valider les systèmes, documenter les écarts et préparer le retour d’expérience |
La règle d’or, ici, est simple : ne pas restaurer à l’aveugle. Si l’attaquant est encore présent, la reprise devient une réinfection. C’est pour cela qu’il faut préserver les preuves, éviter les manipulations inutiles sur les machines critiques et garder une trace des actions menées, même lorsque la pression monte.
La communication compte autant que la technique. Les métiers veulent savoir si la facturation continue, si les clients seront servis, si la paie est intacte, si les données ont fui, et qui décide quoi. Si l’organisation ne sait pas répondre vite, le bruit prend la place du pilotage. Une fois cette mécanique de crise comprise, il reste un dernier sujet indispensable : mesurer la résilience au lieu de la supposer.
Mesurer la résilience avec des indicateurs qui parlent au métier
Je suis prudent avec les tableaux de bord trop techniques. Une entreprise peut avoir de beaux chiffres de sécurité et rester incapable de tenir une crise. Les bons indicateurs doivent être lisibles par l’IT, mais aussi par les responsables métiers et la direction.
| Indicateur | Ce qu’il dit vraiment | Ce que je conseille |
|---|---|---|
| Taux de restauration réussie | La sauvegarde est-elle exploitable ? | Tester régulièrement les restaurations sur les données critiques |
| Temps de bascule en mode dégradé | L’activité peut-elle continuer pendant la crise ? | Le mesurer sur exercice, pas seulement dans un document |
| Écart entre RTO et réalité | Le plan promet-il plus qu’il ne livre ? | Comparer les délais prévus avec les délais réellement observés |
| Couverture MFA sur les comptes sensibles | Les accès les plus dangereux sont-ils protégés ? | Viser 100 % des comptes à privilèges, du VPN et de la messagerie |
| Fréquence des exercices | L’organisation sait-elle réagir sans improviser ? | Faire au moins un exercice de crise par semestre et une restauration test au moins une fois par trimestre |
Je recommande aussi un retour d’expérience systématique après chaque exercice ou incident réel. Le RETEX, s’il est honnête, révèle toujours les mêmes faiblesses : dépendances oubliées, rôles flous, chaînes de validation trop lentes, procédures non lues, ou restaurations qui prennent deux fois plus de temps que prévu. C’est un outil de progression, pas un rituel administratif.
Une résilience mesurée, testée et corrigée régulièrement vaut mieux qu’un plan parfait qui dort dans un dossier partagé. Et en France, ce n’est plus seulement une bonne pratique : le cadre réglementaire pousse aussi à formaliser cette maturité.
Ce que le cadre français change réellement pour la continuité
En France, le sujet a pris une dimension plus concrète avec l’action de l’ANSSI, les exigences sectorielles et l’arrivée progressive de NIS2. Depuis 2026, l’Agence met aussi à disposition le ReCyF, un référentiel de mesures recommandé pour atteindre les objectifs de sécurité visés par la directive. Pour les organisations concernées, cela signifie qu’on ne parle plus seulement de bonnes intentions, mais de mesures structurées, comparables et discutables.
Je trouve ce mouvement sain, à une condition : ne pas réduire la résilience à de la conformité. Se mettre en règle n’empêche pas une crise si les sauvegardes ne restaurent pas, si les comptes à privilèges ne sont pas maîtrisés, ou si les métiers n’ont jamais été entraînés à fonctionner autrement. Le cadre réglementaire fixe un plancher, pas un plafond.
L’exercice massif REMPAR25, organisé par l’ANSSI, a aussi rappelé une évidence souvent sous-estimée : la continuité d’activité ne relève pas uniquement de la DSI. Elle implique les RH, la direction, la communication, les métiers, les achats et les prestataires. C’est précisément pour cela qu’une stratégie de résilience solide doit être pensée comme une capacité d’entreprise, et non comme un simple dossier cyber.
Ce que je vérifierais avant de dire qu’une organisation est réellement résiliente
Si je devais résumer le sujet en une phrase, je dirais ceci : une organisation résiliente n’est pas celle qui n’est jamais touchée, mais celle qui sait décider, continuer et reconstruire sans improvisation. Avant de considérer le travail terminé, je vérifierais trois choses très concrètes : les services vitaux sont clairement nommés, les sauvegardes sont réellement restaurables, et les responsabilités de crise sont comprises autant par les métiers que par l’IT.
Le reste suit plus vite qu’on ne le croit, à condition de répéter les exercices, de corriger les écarts et d’accepter qu’un plan n’a de valeur que s’il a déjà survécu à un test sérieux. C’est cette discipline, beaucoup plus que les slogans de sécurité, qui transforme la résilience en cybersécurité en capacité opérationnelle réelle.