La cyber resilience ne consiste pas à promettre un système inviolable. Elle vise surtout à empêcher qu’un incident technique, un rançongiciel ou une erreur de configuration ne bloque durablement l’activité. Je détaille ici ce qui compte vraiment: les menaces les plus fréquentes, les bons réflexes de reprise, les tests à mener et les contraintes à anticiper en France en 2026.
Les points essentiels à retenir pour renforcer sa résilience numérique
- La résilience combine prévention, détection, réponse et reprise: la sécurité seule ne suffit pas.
- Les attaques qui cassent le plus d’organisations touchent souvent l’identité, les sauvegardes, la chaîne d’approvisionnement logicielle ou le cloud.
- Un bon plan se mesure avec des objectifs de reprise, des rôles clairs et des exercices réalistes.
- Les sauvegardes doivent être isolées et testées, sinon elles rassurent sans protéger.
- En 2026, les équipes en France doivent aussi anticiper le cadre européen sur les produits numériques et la gestion des vulnérabilités.
Ce que recouvre vraiment la cyberrésilience
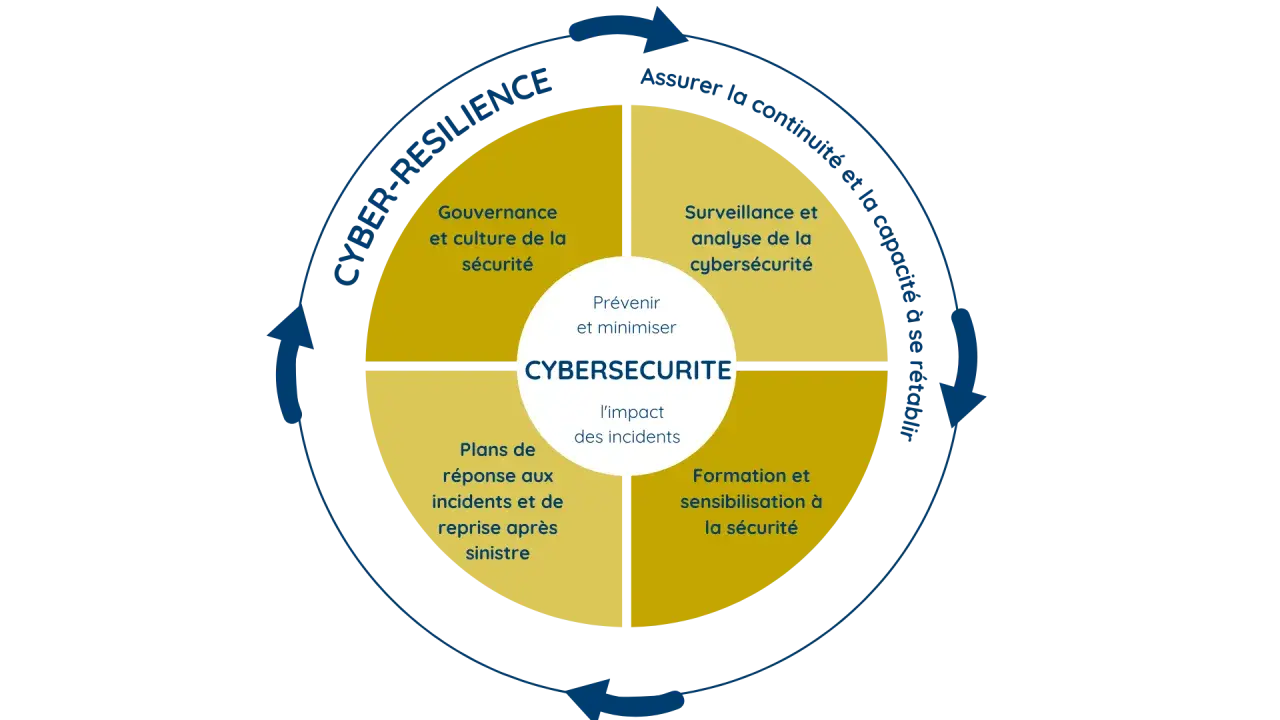
Le NIST décrit la cyberrésilience comme la capacité à anticiper, résister, récupérer et s’adapter face à des conditions adverses. La nuance est importante: la cybersécurité réduit la probabilité d’un incident, tandis que la cyberrésilience réduit sa durée, son impact et sa capacité à paralyser le métier.
Je la résume souvent en une idée simple: une organisation peut subir une compromission sans devenir inopérante si elle a prévu les bons modes dégradés, les bons points de reprise et une chaîne de décision courte. Autrement dit, l’objectif n’est pas l’absence d’attaque, mais la continuité utile de l’activité.
L’erreur la plus courante consiste à confondre protections techniques et vraie capacité de rebond. Un pare-feu, un EDR et quelques règles de filtrage restent indispensables, mais ils ne neutralisent ni le phishing réussi, ni l’attaque sur un fournisseur, ni l’erreur humaine. C’est précisément pour cela qu’il faut regarder les scénarios concrets qui fragilisent le plus souvent une entreprise.
Les menaces qui mettent le plus souvent une organisation à terre
Quand j’analyse des incidents réels, les mêmes familles de risques reviennent avec une régularité presque gênante. Le problème n’est pas seulement la sophistication de l’attaque: c’est la façon dont elle exploite une faiblesse déjà présente dans l’organisation.
| Menace | Effet typique | Réponse minimale efficace |
|---|---|---|
| Rançongiciel | Chiffrement des serveurs, arrêt de production, pression sur les sauvegardes | Sauvegardes immuables, segmentation réseau, comptes à privilèges protégés, restauration testée |
| Compromission d’identité | Connexion légitime d’un attaquant via un mot de passe volé ou réutilisé | Authentification multifacteur, gestion stricte des privilèges, revue régulière des accès |
| Chaîne d’approvisionnement logicielle | Propagation via un éditeur, un prestataire ou une mise à jour compromise | Inventaire des dépendances, contrôle des tiers, exigences contractuelles de sécurité |
| Mauvaise configuration cloud | Données exposées, droits excessifs, interruption de services essentiels | Revue de configuration continue, principes de moindre privilège, politiques automatisées |
| Incident sur des systèmes critiques | Arrêt prolongé d’un ERP, d’une plateforme métier ou d’un environnement industriel | Segmentation, procédures manuelles de secours, priorisation des services vitaux |
Le point commun est clair: ces attaques cassent d’abord la continuité, pas seulement la confidentialité. Si vous ne préparez que la prévention, vous découvrez trop tard que l’organisation n’a pas de plan réaliste pour travailler autrement. C’est pour cela qu’il faut bâtir des piliers opérationnels solides, pas une accumulation d’outils.
Les cinq piliers qui rendent une équipe réellement résiliente
L’ANSSI structure les mesures autour de quatre axes: gouvernance, protection, défense et résilience. Je trouve ce découpage utile, parce qu’il rappelle une vérité simple: la résilience ne se fabrique pas uniquement dans l’outil, mais dans l’organisation, les rôles et les habitudes de travail.
- Gouvernance de crise: qui décide, qui parle, qui arbitre et à quel moment. Sans circuit de validation clair, la crise s’allonge d’elle-même.
- Identités et accès: authentification multifacteur, gestion des comptes à privilèges et moindre privilège. C’est souvent le point de bascule entre un incident contenu et une intrusion durable.
- Segmentation et durcissement: séparer les environnements critiques, isoler les administrateurs, limiter les mouvements latéraux. La segmentation réseau, en pratique, empêche qu’une compromission unique se transforme en incendie généralisé.
- Sauvegardes et restauration: règle 3-2-1-1-0, c’est-à-dire trois copies, sur deux supports, dont une hors site, une copie immuable ou hors ligne, et zéro erreur après test de restauration. C’est l’un des garde-fous les plus rentables que je connaisse.
- Détection et visibilité: centralisation des journaux, corrélation des alertes dans un SIEM, et capacité à qualifier vite ce qui est réel. Un SIEM, c’est un outil de collecte et de corrélation des événements de sécurité; sans triage, il ne vaut pas grand-chose.
Je préfère parler de piliers plutôt que d’outils parce qu’un empilement de produits peut donner une impression trompeuse de solidité. Tant que ces cinq dimensions ne travaillent pas ensemble, la résilience reste théorique. Il faut ensuite la traduire dans un plan de réponse et de reprise qu’une équipe peut réellement exécuter sous pression.
Construire un plan de réponse et de reprise qui tient dans la vraie vie
Je commence toujours par deux chiffres: le RTO, c’est-à-dire le délai maximal de remise en service, et le RPO, c’est-à-dire la quantité de données que l’on accepte de perdre. Sans ces repères, la reprise reste floue, et les priorités se décident dans la panique au lieu d’être déjà arbitrées.
- Cartographier les services critiques: messagerie, ERP, annuaire, outils métier, téléphonie, accès distants. Il vaut mieux en traiter dix bien identifiés que cinquante vaguement listés.
- Associer un propriétaire à chaque service: un nom, un remplaçant, un numéro de contact, une chaîne d’escalade. Dans une crise, l’anonymat coûte du temps.
- Définir les modes dégradés: formulaires papier, processus manuels, circuits hors ligne, messages alternatifs. La continuité n’est pas toujours numérique.
- Préparer le rétablissement: ordre de restauration, dépendances techniques, validation métier, contrôles de sécurité avant remise en production.
- Pré-écrire les messages clés: collaborateurs, clients, fournisseurs, régulateurs, direction. Le temps gagné sur la communication réduit souvent la nervosité et les erreurs.
Une procédure n’a de valeur que si elle a été pensée avec les métiers, pas seulement avec la DSI. Je vois trop de plans magnifiques sur le papier, incapables de survivre au premier appel de crise parce que les rôles, les délais et les dépendances n’avaient jamais été discutés en conditions réalistes. C’est justement pour éviter ce faux sentiment de préparation qu’il faut s’entraîner.

Mesurer et entraîner les réflexes avant l’incident
La résilience se perd vite quand elle n’est pas exercée. Je préfère un exercice simple, mais mené jusqu’au bout, à une simulation brillante jamais débriefée: le vrai enjeu est la coordination, pas le spectacle.
- Exercice sur table: une ou deux heures avec la direction, la DSI, le juridique, la communication et les métiers pour tester les décisions, pas les clics.
- Test de restauration: au moins sur les sauvegardes critiques, avec validation du temps réel de remise en service et de l’intégrité des données.
- Revue des accès: vérifier régulièrement qui possède quels privilèges, pourquoi, et si ces droits sont encore justifiés.
- Simulation de crise élargie: tester la dépendance aux prestataires, au cloud, aux canaux de communication et aux équipes distantes.
Dans la pratique, je recommande un rythme simple: un exercice de crise léger tous les six mois, un test de restauration mensuel pour les actifs critiques et une revue structurée après chaque incident réel ou quasi-incident. Le plus important reste le débriefing: sans plan d’action correctif, l’exercice ne change presque rien. Cette logique de préparation devient encore plus concrète avec le cadre réglementaire qui s’applique en France et dans l’Union en 2026.
Ce que les équipes en France doivent anticiper en 2026
Pour les fabricants de produits comportant des éléments numériques vendus dans l’Union européenne, le cadre CRA impose désormais une discipline bien plus stricte sur les vulnérabilités et les incidents. À partir du 11 septembre 2026, les entreprises concernées devront signaler les vulnérabilités activement exploitées et les incidents graves avec une alerte initiale sous 24 heures, une notification complète sous 72 heures, puis un rapport final dans les délais prévus après disponibilité d’une mesure corrective.
Les obligations principales s’appliqueront à partir du 11 décembre 2027. En pratique, cela oblige à documenter les actifs, tracer les vulnérabilités, organiser un canal d’escalade vers les équipes concernées et clarifier les responsabilités avec les fournisseurs. Pour les organisations qui travaillent avec des tiers, c’est un signal fort: les délais de correction, la qualité de la documentation et la capacité de notification deviennent des critères opérationnels, pas des détails contractuels.
Même si votre entreprise n’est pas fabricante, elle subira indirectement ce mouvement par la chaîne d’approvisionnement. C’est donc le bon moment pour exiger des engagements clairs sur la gestion des correctifs, la transparence des incidents et la qualité des preuves de sécurité. Autrement dit, la résilience n’est plus seulement un sujet technique: elle devient aussi un sujet de conformité et de pilotage fournisseur.Le passage à l’action qui fait vraiment monter la maturité
Si je devais prioriser un programme de cyberrésilience sur 30 jours, je commencerais par trois gestes: sécuriser les identités, valider la restauration des sauvegardes et organiser un exercice de crise simple mais complet. Le reste n’a de valeur que s’il améliore ces trois points.
- Identifier les 10 services les plus critiques pour le métier.
- Nommer un responsable et un remplaçant pour chacun de ces services.
- Tester au moins une restauration complète sur le périmètre le plus sensible.
- Faire jouer un scénario de crise avec la direction et les métiers.
- Suivre cinq indicateurs simples: taux de couverture MFA, succès des sauvegardes, succès des restaurations, délai de détection et délai de reprise.
La bonne nouvelle, c’est qu’une organisation n’a pas besoin d’un programme parfait pour devenir nettement plus robuste. Elle doit surtout rendre sa reprise prévisible, ses décisions plus courtes et ses tests plus fréquents. C’est ce passage du réflexe improvisé au rebond organisé qui transforme la cyberrésilience en avantage opérationnel.