Les points qui changent vraiment le niveau de risque
- Un bon audit couvre l’architecture, la configuration, les accès, le code, les journaux et les dépendances externes, pas seulement les failles visibles depuis l’extérieur.
- Le bon déroulé va du cadrage au re-test, avec une priorisation basée sur l’exposition réelle et la criticité métier.
- Les environnements sensibles gagnent à s’appuyer sur un prestataire qualifié PASSI, surtout quand l’exigence de traçabilité est forte.
- Le rapport n’a de valeur que s’il débouche sur un plan d’action daté, attribué à un responsable et suivi jusqu’à correction.
- Les urgences réelles sont souvent simples à nommer : authentification trop faible, correctifs en retard, segmentation absente, logs inutilisables et privilèges excessifs.
Ce que couvre un audit de sécurité sérieux
Quand je parle d’audit, je ne parle pas d’un simple scan automatisé. Un audit utile cherche à comprendre comment une faiblesse technique, une erreur de configuration ou une mauvaise pratique d’exploitation peut se transformer en incident réel. Autrement dit, je regarde autant la surface d’attaque que la manière dont l’organisation gère ses accès, ses mises à jour, ses sauvegardes et sa détection d’incidents.
Dans un système d’information classique, les zones qui méritent une attention prioritaire sont presque toujours les mêmes :
| Zone auditée | Ce qu’on cherche | Failles fréquentes |
|---|---|---|
| Exposition internet | Services publiés, ports ouverts, règles de filtrage, surface publique | Interfaces oubliées, services de test restés visibles, VPN mal segmenté |
| Identités et privilèges | Comptes à privilèges, MFA, délégations, comptes dormants | Habilitations trop larges, mots de passe partagés, accès admin non tracés |
| Configuration | Durcissement des serveurs, postes, annuaires, pare-feu et cloud | Paramètres par défaut, services inutiles, chiffrement incomplet |
| Applications et code | Erreurs d’authentification, injections, gestion des sessions, secrets exposés | Clés API en clair, contrôle d’accès incomplet, dépendances vulnérables |
| Détection et preuve | Journaux, horodatage, supervision, capacité d’analyse post-incident | Logs absents, conservation trop courte, alertes non centralisées |
Je fais aussi une distinction nette entre la vulnérabilité et le risque. Une faiblesse technique isolée n’est pas forcément critique ; elle le devient si elle est accessible depuis l’extérieur, si l’actif est sensible, ou si un attaquant peut enchaîner plusieurs erreurs pour atteindre une ressource métier. C’est cette lecture combinée qui donne de la valeur à l’audit. La suite logique, c’est donc de structurer la méthode plutôt que d’empiler des outils.
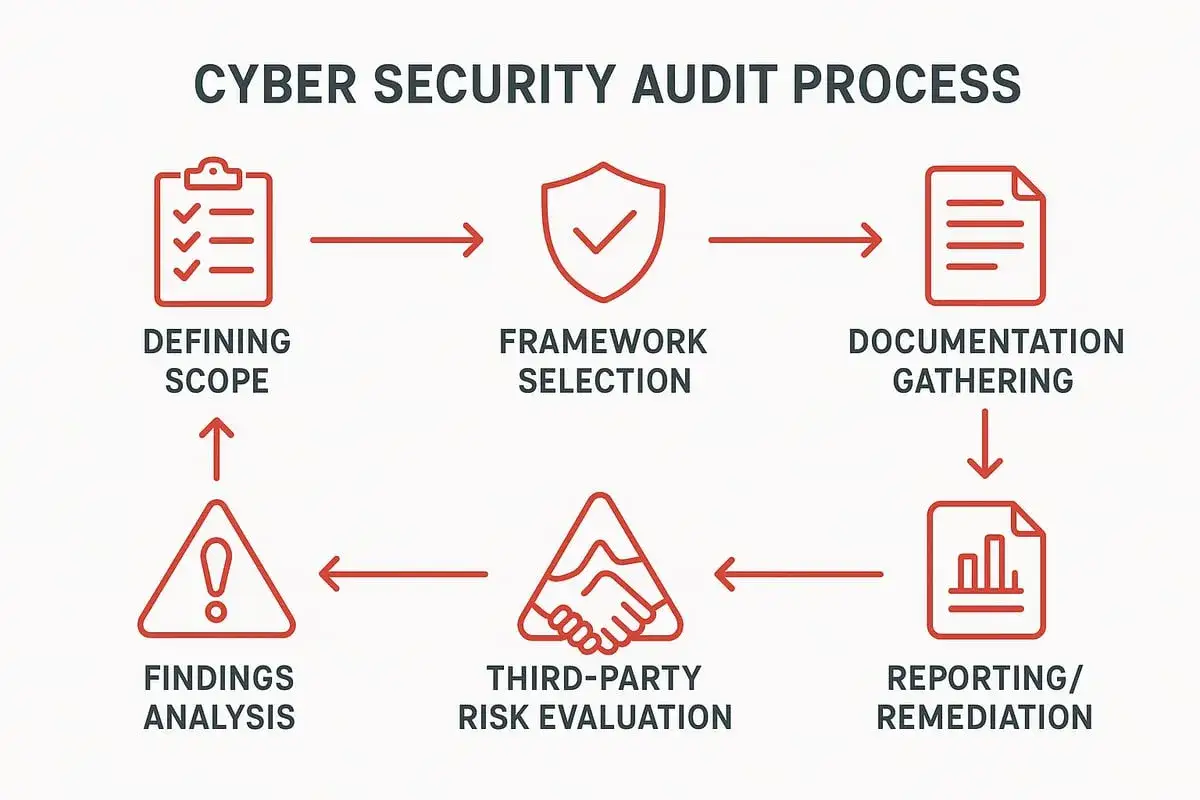
La méthode que j’utilise pour évaluer les vulnérabilités
Définir le périmètre sans flou
Je commence toujours par cadrer ce qui est dans le champ, et surtout ce qui n’y est pas. Un audit bâclé échoue souvent pour une raison simple : le périmètre est trop vague. Je veux savoir quels environnements sont concernés, quelles applications comptent vraiment, quelles interfaces sont exposées, quels fournisseurs interviennent, et quels systèmes sont interdits de test.
Cartographier les actifs et les dépendances
Une bonne cartographie ne se limite pas à une liste de serveurs. Elle doit faire apparaître les flux, les comptes techniques, les dépendances cloud, les outils d’administration, les accès distants et les points de confiance implicites. Dans la pratique, c’est souvent là que je découvre les failles les plus rentables pour un attaquant : un vieux serveur oublié, une interface d’administration trop ouverte ou un compte de service jamais revu.
Tester avec plusieurs angles
Je ne me contente pas d’un scan de vulnérabilités. Un test utile combine au minimum des vérifications de configuration, des contrôles manuels et, selon le contexte, des tests d’intrusion ciblés. Le scan trouve les signaux ; l’analyse humaine les interprète. C’est important, parce qu’un outil remonte facilement des alertes, mais il ne comprend ni la criticité métier, ni la vraisemblance d’un enchaînement d’attaque.
Qualifier le risque, pas seulement la faille
À ce stade, je classe les constats selon trois critères : l’exposition réelle, l’impact potentiel et la facilité d’exploitation. Une vulnérabilité accessible publiquement sur un service critique n’a pas le même poids qu’une faiblesse interne difficile à atteindre. J’ajoute presque toujours une lecture métier : un système peu sensible techniquement peut être très critique si sa panne bloque la production ou la facturation.
Lire aussi : Code à usage unique Microsoft - Guide et solutions s'il n'arrive pas
Corriger puis rejouer les tests
Un audit qui s’arrête au rapport est incomplet. La vraie valeur arrive au moment du re-test, quand on vérifie que les correctifs ont réellement supprimé la faiblesse, sans créer d’effet de bord. C’est aussi le bon moment pour documenter ce qui a été modifié, afin de ne pas recréer la même faille six mois plus tard.
Cette méthode est plus exigeante qu’une simple campagne de scan, mais elle donne un résultat beaucoup plus robuste. Reste une question pratique : selon le contexte, quel type d’audit faut-il choisir en priorité ?
Le bon type d’audit dépend du problème à résoudre
Je vois souvent des organisations commander le mauvais format d’audit. Elles veulent un test d’intrusion, alors que leur problème principal est une configuration cloud trop permissive ; ou elles demandent une revue de code alors que leur exposition vient surtout d’une mauvaise segmentation réseau. Le bon choix dépend du point faible dominant.Selon les référentiels français de qualification, les prestations d’audit peuvent couvrir l’architecture, la configuration, le code source, les tests d’intrusion, ainsi que les volets organisationnel et physique. En pratique, je les lis comme des outils complémentaires, pas comme des doublons.
| Type d’audit | Ce qu’il apporte | Quand je le recommande | Limite principale |
|---|---|---|---|
| Audit de configuration | Repère les écarts de durcissement et les paramètres dangereux | Après un déploiement, une migration ou une refonte d’infrastructure | Ne prouve pas toujours l’exploitabilité réelle |
| Audit d’architecture | Vérifie la logique des flux, des zones de confiance et des dépendances | Quand le SI grossit, se segmente ou se connecte à plusieurs tiers | Peut manquer des détails techniques profonds |
| Audit de code source | Détecte les erreurs de logique, les secrets exposés et les failles applicatives | Pour les applications métiers critiques ou les produits internes | Ne remplace pas les tests d’exploitation ni l’analyse d’environnement |
| Test d’intrusion | Mesure ce qu’un attaquant peut réellement enchaîner | Quand l’exposition externe ou les accès distants sont prioritaires | Très bon pour prouver un scénario, moins pour couvrir tout le SI |
| Audit organisationnel et physique | Évalue les procédures, les droits, les contrôles humains et l’accès aux locaux | Quand les incidents viennent aussi des pratiques internes | Ne remonte pas toutes les failles techniques fines |
Je privilégie rarement une seule méthode. Dans les faits, les meilleures missions combinent au moins deux angles, par exemple configuration plus intrusion, ou architecture plus code. C’est ce qui évite les angles morts. La préparation du périmètre devient alors décisive, car un bon audit peut être ruiné par des infos incomplètes ou des accès mal préparés.
Préparer l’audit pour obtenir un vrai diagnostic
La préparation n’est pas une formalité administrative. Elle conditionne la qualité du résultat. Je préfère un audit bien cadré sur 80 % du périmètre réel qu’un audit théorique sur 100 % du périmètre supposé. Les écarts les plus fréquents viennent rarement de la technique elle-même ; ils viennent d’une documentation obsolète, de comptes de test absents ou d’un périmètre mal négocié.
- Je fixe le périmètre exact, y compris les applications tierces, les environnements de préproduction et les accès distants.
- Je prépare un inventaire d’actifs à jour, avec les IP, les noms de services, les dépendances et les propriétaires techniques.
- Je fournis des comptes de test adaptés, avec des droits réalistes mais contrôlés.
- Je définis une fenêtre de test et un canal d’escalade en cas d’impact sur la production.
- Je vérifie que les sauvegardes, les plans de retour arrière et les procédures d’arrêt d’urgence sont connus.
- Je mets à disposition les journaux nécessaires, parce qu’un audit sans traces exploitables perd une partie de sa valeur.
Le faux bon réflexe consiste à vouloir “rendre l’audit facile” en cachant les problèmes. En réalité, le bon réflexe est d’annoncer ce qui est fragile, ce qui est hors périmètre et ce qui n’est pas prêt. C’est plus honnête et, surtout, plus utile. Une fois l’audit terminé, le vrai travail commence au moment de lire le rapport sans se noyer dans les détails.
Lire le rapport sans se tromper de priorité
Un rapport utile ne se limite pas à une liste de vulnérabilités. Il doit montrer ce qui est non conforme, ce qui est exploitable, ce qui est déjà compensé et ce qui exige un arbitrage de risque. Je cherche toujours quatre éléments : une preuve, un impact, une recommandation et un responsable potentiel.
La CNIL rappelle qu’un audit de sécurité doit déboucher sur un plan d’action suivi au plus haut niveau de l’organisme. C’est exactement la logique que j’applique : sans suivi, le rapport devient un document de plus à archiver. Pour les journaux de sécurité, je garde en tête une fenêtre pratique de 6 à 12 mois, sauf contrainte légale ou besoin contentieux spécifique.
| Niveau | Délai de traitement que je recommande | Exemple de réponse attendue |
|---|---|---|
| Critique | 72 heures maximum | Corriger, isoler ou désactiver la surface concernée sans attendre |
| Élevé | 15 jours | Appliquer un correctif, un durcissement ou une restriction d’accès |
| Moyen | 30 à 60 jours | Planifier une mise à jour, un contrôle de configuration ou une refonte ciblée |
| Faible | 90 jours | Traiter dans le cycle de maintenance normal, avec vérification à froid |
Je me méfie aussi des scores pris isolément. Un CVSS élevé n’implique pas automatiquement une urgence absolue si l’actif est cloisonné et peu exposé. À l’inverse, une faille “moyenne” peut devenir prioritaire si elle touche un compte d’administration, un connecteur critique ou une interface publique. C’est cette lecture contextuelle qui fait la différence entre un simple inventaire et une vraie décision de sécurité.
Le bon rythme d’audit en 2026 dépend plus du risque que du calendrier
En 2026, le cadre français pousse clairement vers un audit pensé comme un programme continu, pas comme une opération ponctuelle. L’ANSSI insiste sur un programme couvrant l’ensemble des systèmes d’information, avec une profondeur et une fréquence alignées sur l’analyse de risque et la criticité des actifs. C’est la bonne logique : plus un système est exposé ou stratégique, plus l’intervalle entre deux vérifications doit se réduire.
Dans ma pratique, je recommande généralement ce rythme de base :
- Systèmes exposés sur internet : contrôle mensuel ciblé et test d’intrusion annuel.
- Applications métiers critiques : audit avant mise en production, puis après chaque refonte importante.
- SI de bureau et environnements internes : revue trimestrielle des points de contrôle majeurs, puis audit complet au moins une fois par an.
- Contexte réglementé ou sensible : recours à un prestataire qualifié PASSI et revalidation après tout changement majeur.
Le point clé, ce n’est pas la fréquence “idéale” sur le papier, c’est la cohérence entre le rythme d’audit, le niveau de menace et la capacité réelle de remédiation. Si une équipe ne peut corriger que deux vulnérabilités par mois, lui imposer une avalanche de constats n’améliore rien. Mieux vaut un audit moins large, mais suivi avec rigueur, qu’une campagne ambitieuse abandonnée en chemin.
Les vérifications que je ne laisserais jamais de côté
Si je devais concentrer l’effort sur quelques contrôles à fort impact, je commencerais par ceux qui réduisent le plus vite l’exposition globale :
- la mise en place d’une authentification multifacteur sur les comptes sensibles ;
- la suppression des comptes dormants et des privilèges surdimensionnés ;
- la correction des services inutiles et des interfaces exposées par erreur ;
- la revue des sauvegardes, avec un test de restauration réel ;
- la centralisation des journaux et leur exploitation active ;
- la gestion des correctifs sur les systèmes et applications les plus visibles.
Ces points ne sont pas spectaculaires, mais ils font souvent la différence entre un SI difficile à attaquer et un système qui se défend surtout sur le papier. Si je devais résumer l’esprit d’un bon audit, je dirais ceci : il doit montrer où le système casse, pourquoi il casse, et dans quel ordre réparer pour regagner le plus de sécurité avec le moins d’effort inutile. C’est précisément ce qui rend l’audit utile au quotidien, et pas seulement conforme sur le plan documentaire.