Les points essentiels à garder en tête avant de synchroniser votre annuaire
- Microsoft parle désormais de Microsoft Entra ID, même si beaucoup continuent à dire Azure AD par habitude.
- Cloud Sync est aujourd’hui la voie recommandée pour la plupart des nouveaux scénarios hybrides, surtout si vous voulez réduire la charge d’exploitation.
- Connect Sync reste utile dès que vous avez besoin de synchronisation des appareils, de règles avancées ou de gros volumes très spécifiques.
- La latence n’est pas instantanée: comptez souvent 2 à 5 minutes pour la synchronisation du hash de mot de passe et environ 10 à 20 minutes pour les objets utilisateurs et groupes.
- Les deux vrais sujets de réussite sont le périmètre de synchronisation et la qualité des attributs dans l’Active Directory local.
Ce que recouvre la synchronisation entre Active Directory et Microsoft Entra ID
Quand on parle de synchronisation d’annuaire, on parle d’abord d’aligner les identités entre l’Active Directory local et Microsoft Entra ID, l’ancien Azure AD. L’idée n’est pas de dupliquer bêtement un répertoire, mais de faire circuler les bons objets, avec les bons attributs, au bon moment: utilisateurs, groupes, contacts, parfois des extensions d’attributs, et selon les cas des informations liées au mot de passe ou au cycle de vie des comptes.
Je vois souvent une confusion entre synchronisation, authentification et fédération. Ce ne sont pas les mêmes couches. La synchronisation prépare les identités dans le cloud, l’authentification décide comment l’utilisateur prouve qu’il est bien lui, et la fédération ajoute une couche externe ou dédiée pour certains scénarios. Si vous mélangez ces notions, vous choisissez vite le mauvais outil ou vous attendez d’un composant ce qu’il ne fait pas.
Dans une PME ou une ETI, le gain principal est très concret: un compte cohérent pour Microsoft 365, les applications SaaS, les accès conditionnels et les outils de gouvernance. En revanche, la synchronisation ne nettoie pas votre annuaire à votre place. Si les UPN sont incohérents, si les adresses proxyAddress sont dupliquées ou si les OU sont mal structurées, le problème remonte simplement dans le cloud. Et c’est précisément pour cela que je commence toujours par le modèle de données avant de parler serveur ou agent.
Cette base posée, la vraie question devient rapidement le choix de la technologie, parce que tous les scénarios hybrides ne se traitent pas avec le même niveau d’exigence.
Cloud Sync ou Connect Sync, je ne les mets pas sur le même plan
En 2026, la tendance Microsoft est claire: Cloud Sync est le chemin privilégié pour la majorité des nouveaux déploiements, alors que Connect Sync reste présent pour les environnements qui dépendent encore de fonctions avancées ou de contraintes historiques. Je ne les compare pas comme deux produits équivalents, mais comme deux réponses à des besoins différents.
| Critère | Cloud Sync | Connect Sync | Ce que j’en conclus |
|---|---|---|---|
| Architecture | Agents légers + orchestration cloud | Serveur de synchronisation local | Cloud Sync réduit la dette d’exploitation |
| Gestion | Configuration centralisée dans Microsoft Entra | Configuration locale sur le serveur | Cloud Sync est plus simple à administrer à distance |
| Haute disponibilité | Plusieurs agents actifs et bascule automatique | Un serveur principal, donc un point de fragilité | Cloud Sync est plus robuste en production |
| Forêts disjointes | Bien gérées | Plus complexes à traiter | Cloud Sync est intéressant en contexte fusion-acquisition |
| Synchronisation des appareils | Non | Oui | Si vous avez besoin de Hybrid Azure AD Join, gardez Connect |
| Règles avancées | Plus limitées, avec expression builder | Très complètes | Connect garde l’avantage pour les transformations complexes |
| Volume par domaine | Jusqu’à 150 000 objets | Sans limite comparable dans ce cadre | Au-delà, je valide le besoin avec prudence |
| Groupes volumineux | Limite à 50 000 membres | Jusqu’à 250 000 membres | Connect reste plus confortable pour les très gros groupes |
| Password hash sync et writeback | Oui | Oui | Le socle fonctionnel est bien couvert des deux côtés |
| Exchange hybrid | Oui | Oui | Ce n’est plus un critère de départage majeur |
En pratique, je recommande Cloud Sync quand l’objectif est de moderniser sans alourdir l’infrastructure, notamment si vous avez plusieurs serveurs, des équipes réparties ou des forêts AD séparées qui n’ont pas vocation à être consolidées. Je recommande plutôt Connect Sync si votre architecture dépend encore de la synchronisation des appareils, de règles de flux très spécifiques, d’une gestion avancée des relations entre forêts ou de groupes massifs qui dépassent les limites de Cloud Sync.
Autre point utile: Cloud Sync supporte aussi la synchronisation des groupes vers Active Directory dans certains scénarios cloud-to-AD. C’est intéressant quand Microsoft Entra ID devient plus qu’une simple cible de synchro et commence à jouer un rôle d’autorité sur certains objets. Cette possibilité n’est pas à confondre avec la synchronisation classique des utilisateurs, et c’est justement ce qui fait la différence dans des architectures hybrides plus mûres.
Une fois le bon outil choisi, il faut encore comprendre le mécanisme réel de circulation des données, parce que c’est là que les délais, les dépendances et les incidents se jouent.
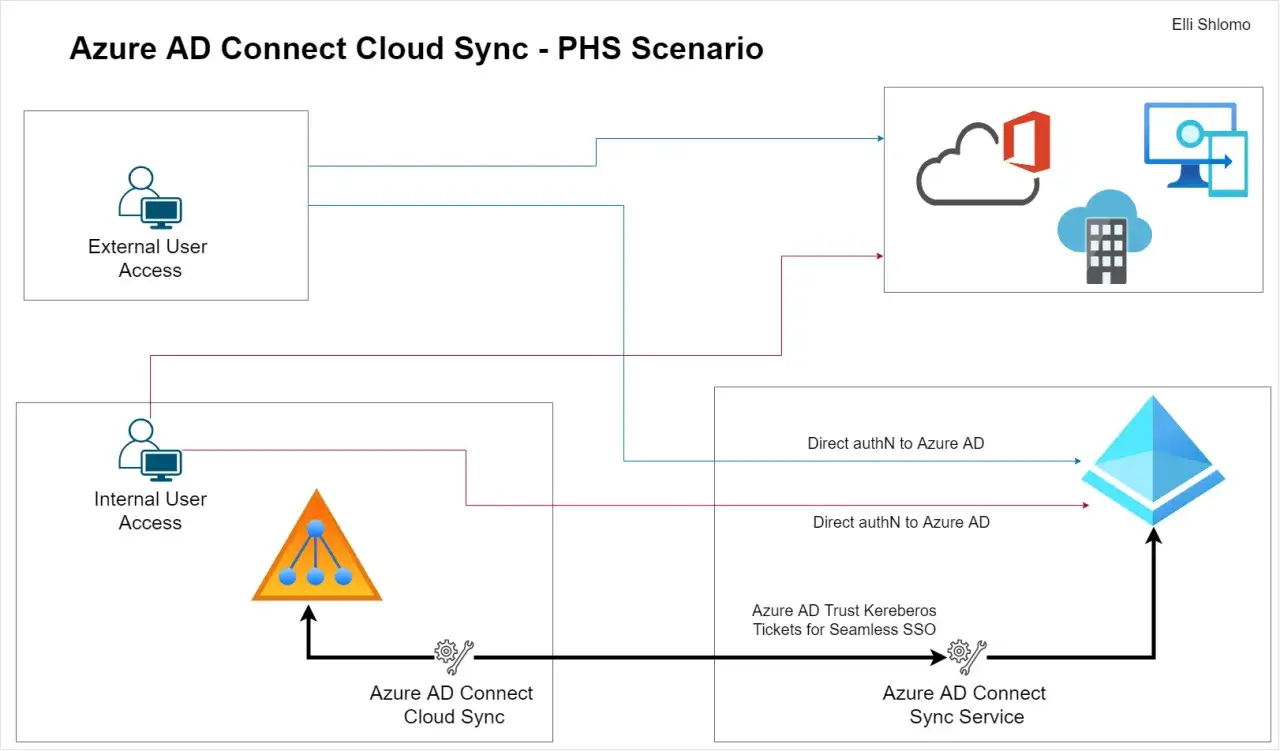
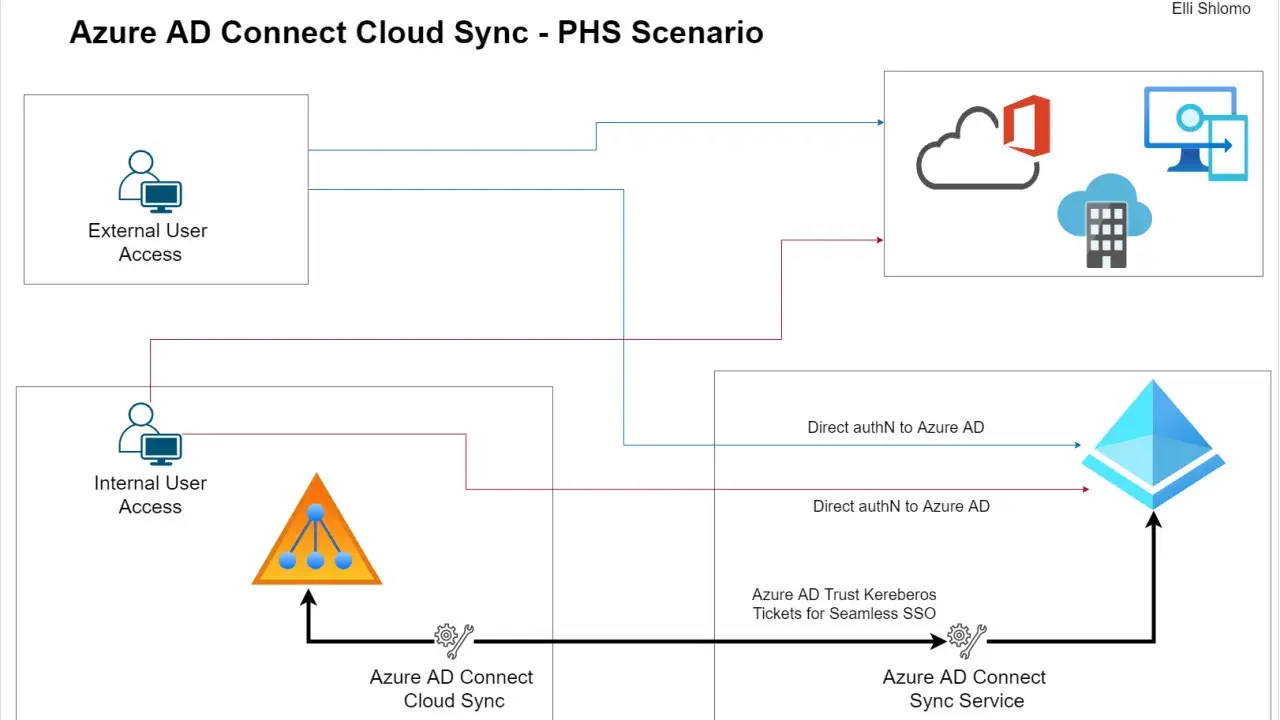
Comment fonctionne le flux de synchronisation au quotidien
Cloud Sync repose sur un agent de provisioning installé côté réseau local, qui échange avec le service Microsoft dans le cloud. L’architecture est volontairement légère: l’agent maintient une connexion sortante, ce qui évite d’exposer des ports entrants inutiles. Microsoft s’appuie sur des mécanismes proches de SCIM, ce qui permet un échange standardisé des informations d’identité.
Le fonctionnement réel est plus simple à retenir qu’il n’y paraît. Le service cloud déclenche une demande, l’agent interroge l’Active Directory local, applique les règles de périmètre et les mappages d’attributs, puis renvoie les données à Microsoft Entra ID. Le moteur conserve l’état de synchronisation et traite les mises à jour incrémentales. Ce point est important, car la plupart des gens imaginent une copie intégrale permanente alors qu’il s’agit surtout d’un traitement par différences.
Pour les délais, je préfère être précis plutôt que rassurant. La synchronisation du hash de mot de passe est prévue toutes les 2 à 5 minutes. La synchronisation des utilisateurs et des groupes se fait souvent dans une fenêtre d’environ 10 à 20 minutes, mais ce délai varie selon le volume de changements en attente. Autrement dit, un petit lot passe vite, un gros lot s’étale davantage. Ce n’est pas un bug, c’est la logique du moteur de provisioning.
Cloud Sync a aussi un avantage pratique que l’on sous-estime souvent: vous pouvez déployer plusieurs agents pour la continuité de service. Si l’un d’eux tombe, les autres prennent le relais. Je trouve ce point plus important que la fiche marketing, parce qu’en production ce sont les indisponibilités courtes, les maintenances et les aléas réseau qui coûtent du temps, pas les grandes théories d’architecture.
Cette mécanique fonctionne bien, mais elle suppose une préparation sérieuse. Et c’est là que beaucoup de projets gagnent ou perdent des semaines.
La préparation technique qui évite la plupart des incidents
Avant de lancer la première synchronisation, je fais toujours la même vérification: quels objets doivent réellement sortir de l’Active Directory local, et avec quels attributs. Cette question a l’air basique, mais elle évite la moitié des surprises. Une scope trop large crée du bruit, une scope trop étroite crée des trous dans l’annuaire cloud.
Définir un périmètre propre
Le plus simple reste souvent une synchronisation basée sur les OU ou sur un groupe pilote, à condition de savoir ce que vous faites. Je privilégie les OU quand l’organisation du répertoire est saine, parce que c’est plus lisible pour les équipes d’exploitation. Les filtrages trop sophistiqués sont séduisants au début, mais ils deviennent vite difficiles à maintenir si personne ne documente les règles métier associées.
Nettoyer les attributs critiques
Les attributs qui font mal quand ils sont mal tenus sont toujours les mêmes: UPN, adresse SMTP principale, proxyAddresses, manager et, selon vos usages, certaines extensions d’attributs. Un doublon sur un UPN ou une mauvaise adresse principale peut provoquer des conflits d’identité difficiles à dénouer. Je conseille de corriger ces points avant la mise en production, pas pendant le premier mois d’incidents.
Vérifier l’architecture d’hébergement
Le provisioning agent peut être installé sur un serveur dédié ou sur un contrôleur de domaine, mais pas sur Server Core. Il n’existe pas non plus de staging server pris en charge pour l’agent de Cloud Sync. Ces deux détails comptent, car ils délimitent ce que vous pouvez industrialiser ou non. Si vous aviez un vieux réflexe de “serveur de secours caché” pour tout tester, il faut revoir le modèle.
Lire aussi : Windows Autopilot - Quel mode de déploiement choisir avec Intune ?
Prévoir le volet réseau et exploitation
Comme le service fonctionne en sortie, je vérifie surtout la connectivité vers les services Microsoft, les règles de proxy éventuelles et la supervision des agents. J’anticipe aussi les mises à jour automatiques, parce que l’agent est maintenu par Microsoft et ne se gère pas comme un binaire maison que l’on fige pendant deux ans. Sur un plan opérationnel, c’est un avantage, à condition d’accepter le rythme de maintenance qui va avec.
Quand ces bases sont propres, le déploiement devient beaucoup plus lisible. Il reste pourtant quelques pièges très classiques, et je les vois revenir même dans des environnements matures.
Les erreurs de terrain que je vois le plus souvent
Je pourrais résumer les incidents de synchronisation en une phrase: ils sont rarement dus au moteur lui-même, et presque toujours au périmètre, aux attributs ou aux hypothèses de départ. Pour être concret, voici les erreurs que je rencontre le plus souvent et ce qu’elles provoquent.
| Erreur | Effet réel | Ce que je corrige |
|---|---|---|
| Synchroniser trop d’OU d’un coup | Charge inutile, objets non prévus, nettoyage compliqué | Je commence par un périmètre pilote et j’élargis ensuite |
| Négliger les UPN ou les proxyAddresses | Conflits d’identité, doublons, comptes mal corrélés | Je fais un inventaire préalable des attributs critiques |
| Attendre une synchronisation instantanée | Impatience, faux diagnostics, escalades inutiles | J’explique les cycles de 2 à 5 minutes et de 10 à 20 minutes |
| Oublier que certains scénarios ne sont pas supportés | Blocage tardif du projet | Je valide dès le départ les besoins en device sync, guest users et staging |
| Supprimer une configuration sans nettoyer le périmètre | Objets orphelins encore visibles dans Microsoft Entra ID | Je vide d’abord la scope, puis je désactive la configuration |
| Déplacer un utilisateur d’une OU gérée par Cloud Sync vers une OU gérée par Connect | Suppression puis recréation du compte côté cloud | Je traite ces migrations comme des changements d’identité, pas comme de simples déplacements |
Il y a aussi des limites qu’il faut accepter sans contorsion: Cloud Sync ne prend pas en charge la synchronisation des appareils, les comptes invités, ni certains scénarios avancés de filtrage. Si vous avez besoin de règles très fines ou d’objets cross-forest complexes, Connect Sync garde sa place. J’ajoute souvent ce rappel parce qu’un projet peut être techniquement bon et malgré tout être le mauvais choix pour un contexte précis.
La règle que j’applique est simple: si l’on commence à empiler des exceptions, des contournements et des attentes non couvertes, c’est le signal qu’il faut revenir au besoin métier réel, pas forcer l’outil à faire ce qu’il ne sait pas faire proprement.
Ce que je recommande avant de standardiser votre identité hybride
Si je devais lancer un projet de synchronisation aujourd’hui, je ferais d’abord un inventaire très concret: taille du parc d’objets, structure des OU, qualité des UPN, dépendance à Hybrid Azure AD Join, présence d’Exchange hybrid, taille des groupes et besoin éventuel de règles avancées. Ce sont ces paramètres qui tranchent, pas le slogan du moment.
Ensuite, je déroulerais le projet en trois temps. D’abord un pilote réduit sur quelques comptes représentatifs. Ensuite une phase de validation métier, avec des cas simples et des cas limites. Enfin seulement, l’extension du périmètre. Cette approche paraît lente sur le papier, mais elle évite les corrections massives après coup, qui coûtent toujours plus cher que trois jours de préparation sérieuse.
Je retiens aussi une chose importante: en 2026, la stratégie Microsoft pousse clairement vers Cloud Sync pour les nouveaux scénarios hybrides, mais cela ne veut pas dire que Connect Sync est obsolète pour tout le monde. Le bon choix reste celui qui respecte votre architecture, vos contraintes et vos usages réels. Si vous partez de là, la synchronisation devient un outil de simplification; si vous partez d’une hypothèse trop optimiste, elle devient vite un nouveau sujet d’exploitation.
La meilleure décision, à mon sens, consiste à documenter ce que vous synchronisez, pourquoi vous le synchronisez et ce que vous refusez de synchroniser. C’est ce cadre qui protège le projet, bien plus que le paramétrage initial seul.