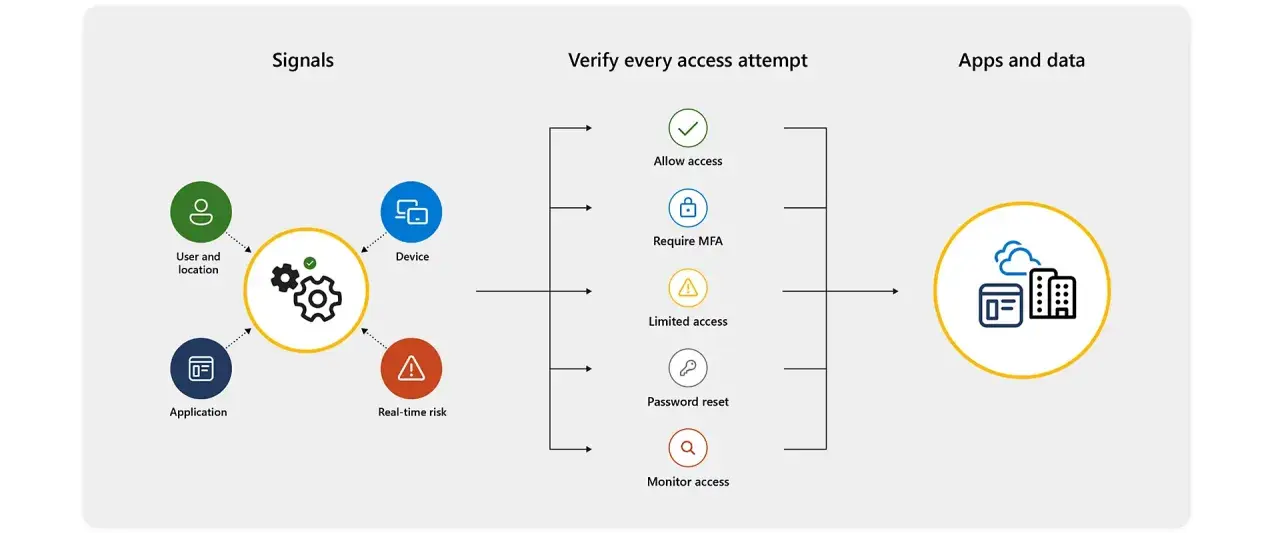
Dans une organisation, autoriser l’accès à une application ne devrait jamais se résumer à un mot de passe validé une fois pour toutes. L’accès conditionnel sert justement à décider qui peut entrer, depuis quel appareil et dans quel contexte, en s’appuyant sur des signaux comme la localisation, l’état du terminal ou le niveau de risque. Je vais expliquer comment ce contrôle fonctionne, comment je le règle pour qu’il soit utile au quotidien et quels pièges je surveille en priorité.
Les points essentiels à retenir avant de le déployer
- Le principe repose sur une logique simple de type si alors : si le contexte est jugé acceptable, l’accès passe, sinon il est renforcé ou bloqué.
- Les signaux les plus utiles sont l’identité, l’appareil, la localisation, le niveau de risque et le type d’application ciblée.
- Je commence presque toujours en mode report-only avant d’activer une règle en production.
- Les politiques les plus rentables protègent d’abord les comptes privilégiés, les applications sensibles et les flux hérités trop faibles.
- Une bonne politique dépend autant de ses exclusions, de ses tests et de ses dépendances que de ses critères de blocage.
Pourquoi l’accès conditionnel change la gestion des accès
Dans la logique Zero Trust décrite par le NIST, je ne pars jamais du principe qu’un utilisateur ou un réseau est fiable par défaut. Je traite chaque demande comme un cas à évaluer: identité, appareil, application, localisation et niveau de risque entrent dans la même décision.
Concrètement, ce contrôle intervient après l’authentification initiale. Il ne remplace donc ni le mot de passe ni l’authentification multifacteur (MFA); il décide plutôt ce qu’il faut exiger ensuite: validation supplémentaire, poste conforme, restriction de session ou blocage total. C’est ce qui le rend plus précis qu’un filtrage réseau classique, mais aussi plus exigeant à concevoir.
Un autre point mérite d’être clair: ce mécanisme n’est pas conçu comme une défense de première ligne contre un déni de service. Il protège les accès légitimes en fonction du contexte; il ne sert pas à absorber un flot massif de trafic. Une fois cette frontière posée, on peut regarder les signaux qui alimentent la décision.
Les signaux que je privilégie dans la décision
Je privilégie toujours les signaux qui disent quelque chose de vérifiable sur le niveau de confiance réel. Une IP seule ne suffit pas, un appareil seul ne suffit pas non plus; c’est leur combinaison qui permet d’éviter les faux positifs sans ouvrir trop largement.| Signal | Ce qu’il m’apporte | Ce que j’en fais | Limite pratique |
|---|---|---|---|
| Identité et groupe | Je sais si je vise un utilisateur standard, un administrateur ou un ensemble précis | Je réserve des règles plus strictes aux profils sensibles | Un groupe mal maintenu finit par inclure des personnes qui ne devraient pas être dedans |
| État de l’appareil | Je vois si le poste est conforme, géré ou simplement inconnu | J’exige souvent un appareil conforme pour les données critiques | La conformité n’est pas une preuve absolue de sécurité, seulement un bon signal de base |
| Localisation ou réseau | Je repère des connexions inhabituelles ou des zones à surveiller | Je peux renforcer l’accès hors site ou bloquer certains pays | Une adresse IP d’entreprise ou un VPN ne garantit pas un environnement sûr |
| Niveau de risque | Je détecte des comportements anormaux ou des connexions suspectes | Je déclenche une MFA supplémentaire, un blocage ou une révision manuelle | Les signaux de risque doivent être interprétés avec prudence pour éviter de pénaliser le quotidien |
| Application cible | Je peux différencier une messagerie grand public d’un ERP ou d’un espace RH | Je protège plus sévèrement les applications sensibles | Les dépendances entre applications compliquent parfois la règle de façon invisible |
| Type de client ou flux | Je distingue les connexions modernes des flux plus anciens ou plus risqués | Je bloque les scénarios faibles et je garde les chemins modernes | Un ancien flux peut encore être utilisé par un outil métier oublié |
Construire une politique qui tient en production
Quand je construis une politique, je sépare toujours ce qui décide de l’accès et ce qui encadre la session. Cette distinction évite de tout faire porter par une seule règle, ce qui rend les politiques plus compréhensibles et beaucoup plus simples à dépanner.
Les deux familles de contrôles que je distingue toujours
| Famille | Rôle | Exemple concret | Quand je la choisis |
|---|---|---|---|
| Contrôles d’octroi | Décident si l’accès peut être accordé | Exiger MFA, un appareil conforme ou bloquer un client hérité | Quand je veux fixer une barrière nette à l’entrée |
| Contrôles de session | Encadrent ce qui se passe après l’ouverture de session | Réauthentification plus fréquente, limitations sur les téléchargements, restrictions d’application | Quand j’ai besoin de durcir sans bloquer toute l’activité |
En pratique, je trouve les contrôles de session très utiles pour les applications sensibles, parce qu’ils réduisent le risque sans casser tout le parcours utilisateur.
Lire aussi : Cybersécurité - Définition et plan d'action pour réduire vos risques
Ma méthode de déploiement en cinq étapes
- Je commence par un périmètre réduit. J’applique la politique à une application critique ou à un petit groupe d’utilisateurs avant d’élargir.
- Je pars d’une exigence simple. MFA ou appareil conforme suffit souvent pour lancer un premier socle propre.
- Je garde des comptes d’urgence exclus. Sans chemin de secours, une mauvaise règle peut bloquer l’administration au pire moment.
- Je teste en mode report-only. C’est la meilleure façon de voir l’effet réel sans casser la production. J’utilise ensuite What If pour simuler les cas limites.
- Je ne passe au blocage qu’après les preuves. Quand les journaux montrent que la règle se comporte comme prévu, j’active progressivement le mode strict.
Cette méthode paraît prudente, mais c’est elle qui évite les surprises. Une politique bien pensée sert ensuite de base à des usages très concrets.
Les cas d’usage qui apportent le plus de valeur
Les cas d’usage les plus rentables sont rarement ceux qui impressionnent le plus en réunion; ce sont ceux qui réduisent vraiment la surface d’attaque. Je regarde toujours en priorité ce qui protège les identités les plus exposées et les applications les plus sensibles.
- Bloquer l’authentification héritée. Elle contourne souvent les protections modernes et reste une porte d’entrée trop commode pour les attaques opportunistes.
- Protéger les comptes privilégiés. Pour un administrateur, je durcis davantage que pour un utilisateur standard, parce que l’impact d’une compromission est sans commune mesure.
- Autoriser les applications SaaS seulement depuis un poste conforme. C’est particulièrement utile avec le travail hybride, quand les accès se font depuis des terminaux variés.
- Encadrer les partenaires et prestataires. Je préfère leur donner un accès étroit, vérifiable et réversible plutôt qu’une confiance large difficile à contrôler ensuite.
Le meilleur signal de maturité, à mes yeux, n’est pas le nombre de règles créées, mais le fait qu’elles correspondent vraiment aux risques métier. C’est là qu’apparaissent les erreurs les plus coûteuses.
Les erreurs qui créent des blocages inutiles
Le principal défaut des déploiements précipités, c’est qu’ils traitent tous les utilisateurs comme s’ils avaient le même niveau de risque et les mêmes besoins. Dans la vraie vie, les écarts entre un collaborateur nomade, un administrateur et un prestataire externe sont trop grands pour une politique uniforme.
| Erreur fréquente | Effet réel | Correction que j’applique |
|---|---|---|
| Multiplier les exclusions | La politique devient lisible en apparence, mais elle perd sa valeur de protection | Je limite les exceptions et je les documente comme des cas temporaires ou strictement justifiés |
| Se fier à une seule localisation “de confiance” | Une IP d’entreprise ou un VPN ne garantit pas un environnement sain | Je combine toujours localisation, appareil et identité |
| Oublier les dépendances applicatives | Une règle peut sembler correcte mais casser un service indirectement lié | Je vérifie les flux de bout en bout avant d’activer le blocage |
| Passer directement en mode strict | Les utilisateurs découvrent la règle au moment où elle les impacte le plus | Je maintiens une phase d’observation et je corrige les faux positifs avant l’activation |
| Négliger l’accès d’urgence | Une mauvaise configuration peut bloquer l’administration | Je garde un chemin de secours indépendant de la politique principale |
Je vois souvent le même schéma: la sécurité augmente sur le papier, puis l’équipe support absorbe le coût des blocages. Pour éviter ça, il faut tester la politique comme un vrai parcours utilisateur, pas comme une simple case à cocher.
Ce que je teste avant de généraliser la politique
Avant d’élargir une politique, je veux avoir répondu à une question simple: est-ce qu’elle protège sans rendre le travail quotidien pénible? Pour le savoir, je ne me contente jamais d’un cas nominal; je teste des scénarios ordinaires et des cas tordus.
- un utilisateur standard sur un poste géré;
- un administrateur depuis un appareil conforme, puis depuis un appareil non conforme;
- une connexion via VPN et une connexion hors réseau d’entreprise;
- un accès depuis une localisation inhabituelle;
- un client ancien ou un flux d’authentification moins sûr;
- une application critique avec ses dépendances complètes.
Je regarde ensuite les journaux de connexion, les refus répétés et les demandes de validation supplémentaires pour voir où la règle accroche. Si le même frein revient plusieurs fois, je corrige la logique avant de généraliser.
Si je devais retenir une seule approche, ce serait celle-ci: je protège d’abord les identités à fort impact, je teste en observation, j’ajoute les contraintes de session seulement quand elles apportent un vrai gain, puis j’élargis progressivement. C’est cette discipline qui transforme un contrôle d’accès en levier solide de cybersécurité, pas en source de friction permanente.