Les points à retenir avant de choisir une plateforme SaaS
- Un service SaaS repose en général sur une architecture partagée, avec une isolation logique des clients et une exploitation centralisée.
- La vraie différence entre les offres se joue sur l’isolation, la réversibilité, la conformité, les sauvegardes et la qualité de l’observabilité.
- Un SLA à 99,9 % correspond à environ 43 minutes d’arrêt mensuel théorique sur 30 jours; à 99,99 %, on tombe à environ 4 minutes.
- La sécurité ne se limite pas au chiffrement: gestion des accès, journaux, segmentation, sauvegardes et plan de reprise comptent autant.
- Pour la France, la localisation des données, le RGPD et, selon les cas, HDS ou SecNumCloud doivent être vérifiés avant la mise en production.
Ce qu’implique réellement un hébergement SaaS
Quand on parle de SaaS, on parle d’un logiciel exploité à distance par un fournisseur, auquel le client accède via le web, une API ou une application connectée. Dans les faits, cela change tout: le fournisseur gère l’infrastructure, les mises à jour, une grande partie de la sécurité et une partie du support, tandis que le client garde la responsabilité de ses usages, de ses droits d’accès et de ses données.
Je fais toujours une distinction simple. L’IaaS fournit des briques d’infrastructure, le PaaS fournit une plateforme pour déployer du code, et le SaaS fournit le logiciel déjà opéré. C’est ce dernier modèle qui attire les équipes métier, car il réduit le temps d’exploitation interne, mais c’est aussi celui qui impose de regarder de près la gouvernance, les contrats et la réversibilité.
Autrement dit, l’enjeu n’est pas seulement de savoir où tourne l’application. Il faut surtout comprendre qui patch, qui supervise, qui restaure, qui peut accéder aux données en cas d’incident et comment la prestation s’arrête proprement si besoin. Cette lecture pratique est la seule qui évite les mauvaises surprises, et elle prépare directement la question de l’architecture.
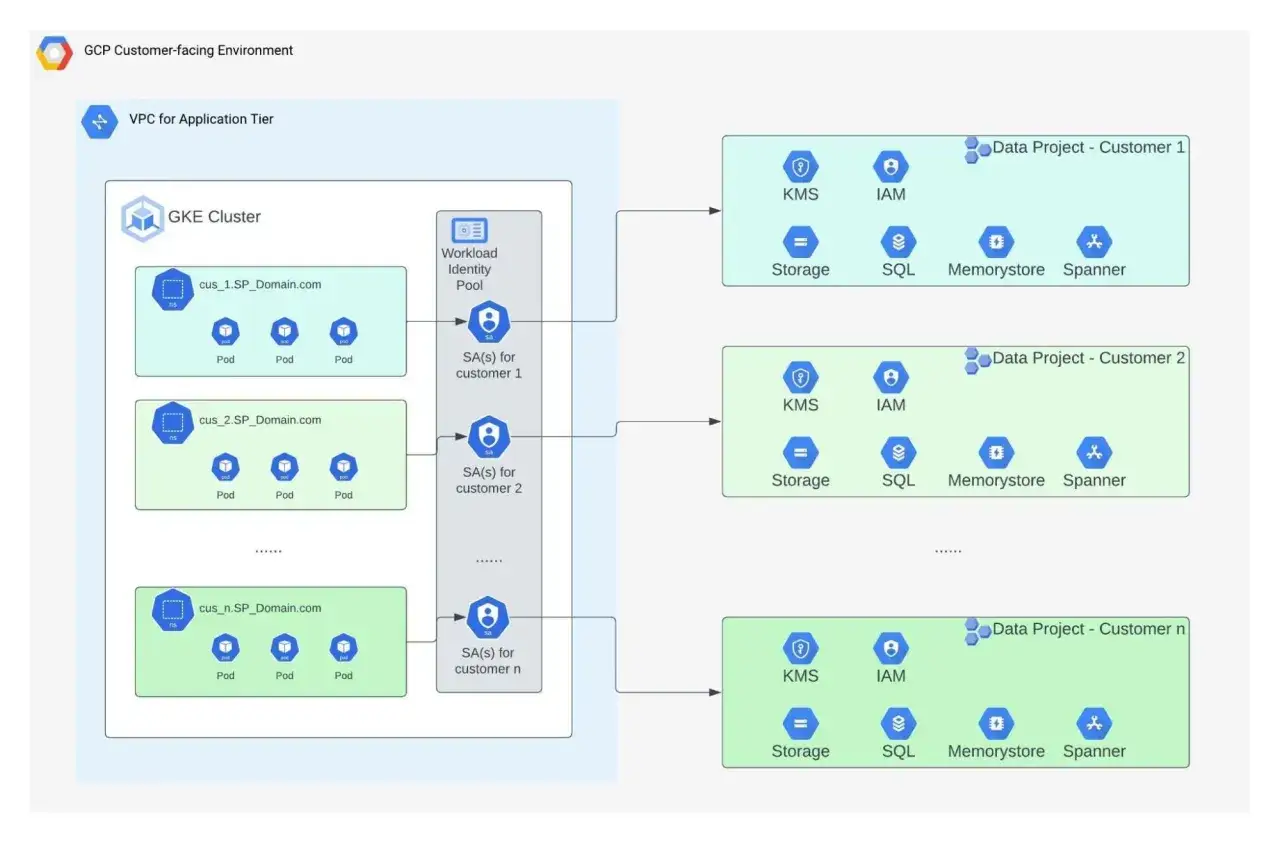
L’architecture qui tient la charge et limite les incidents
Dans une plateforme SaaS bien construite, les clients partagent souvent une partie de l’infrastructure, mais pas forcément les mêmes bases de données, les mêmes volumes ni le même niveau d’isolation. Le mot-clé ici est multi-tenancy, c’est-à-dire la capacité à servir plusieurs organisations tout en séparant leurs données et leurs droits d’accès. C’est économiquement efficace, mais cela n’a d’intérêt que si la conception suit.
| Composant | Rôle | Point de vigilance |
|---|---|---|
| Authentification et SSO | Identifier les utilisateurs et centraliser les accès | Gestion du MFA, délégation d’identité, révocation rapide des comptes |
| Base de données | Stocker les données métier | Isolement par schéma, par base ou par cluster selon le niveau de sensibilité |
| Stockage de fichiers | Conserver documents, exports, pièces jointes | Chiffrement, durée de rétention, suppression effective |
| Files et traitements asynchrones | Absorber les pics et déporter les tâches lourdes | Files bloquées, reprise après panne, idempotence des jobs |
| Observabilité | Logs, métriques et traces | Corrélation des incidents, alertes utiles, conservation des journaux |
Je regarde aussi la capacité à encaisser un incident sans faire tomber tout le service. Un bon design isole les composants critiques, limite les dépendances inutiles et permet de faire évoluer une partie du système sans casser le reste. C’est souvent là que les projets débutants se trompent: ils pensent “serveur” alors qu’il faut penser système complet, avec ses flux, ses dépendances et ses points de rupture.
Sur la disponibilité, les chiffres méritent d’être lus avec prudence. Un SLA de 99,9 % représente environ 43 minutes d’interruption mensuelle théorique sur 30 jours; 99,95 % tombe autour de 22 minutes; 99,99 % descend à environ 4 minutes. Ce n’est pas un détail marketing: c’est une manière très concrète de mesurer ce que le fournisseur vous promet vraiment. Une fois cette base comprise, la sécurité devient la deuxième couche incontournable.
Sécurité, RGPD et responsabilité partagée
Le cloud ne déplace pas la responsabilité juridique. La CNIL rappelle que l’usage du cloud exige des garanties suffisantes de sécurité, mais aussi une vraie vigilance du client sur les accès, la localisation des données et la sous-traitance. En pratique, cela veut dire qu’un contrat solide et une configuration propre comptent autant que le discours commercial du fournisseur.
Je conseille de vérifier au minimum les points suivants:
- Le principe du moindre privilège, c’est-à-dire l’attribution des accès strictement nécessaires à chaque rôle.
- Le chiffrement des données en transit et au repos, avec une politique claire sur la gestion des clés.
- Les journaux d’audit, leur conservation et leur exploitation réelle en cas d’incident.
- Les sauvegardes testées, pas seulement déclarées, avec une restauration vérifiée périodiquement.
- Le plan de reprise d’activité, avec des objectifs explicites de RPO et de RTO.
Le RPO indique la perte de données maximale acceptable, et le RTO le temps de retour au service après incident. Ce sont deux indicateurs que je préfère voir écrits noir sur blanc, car ils révèlent la maturité réelle d’une offre. Sans eux, on parle de continuité de service de manière abstraite, ce qui ne sert à rien le jour où un incident survient.
Pour la France, il faut en plus regarder la localisation effective des données et les éventuels transferts hors UE. Si l’activité touche la santé, le cadre HDS devient central; si les exigences de souveraineté ou de sensibilité sont très élevées, SecNumCloud peut aussi entrer dans l’équation. La logique reste la même: plus la donnée est sensible, plus la preuve de maîtrise doit être nette. Une fois ces garde-fous posés, il devient plus simple de comparer les modèles de déploiement.
Multi-tenant, single-tenant ou cloud privé
Les offres SaaS se ressemblent parfois en surface, mais les choix d’architecture derrière changent fortement l’expérience, les coûts et le niveau d’isolement. Je résume souvent le débat ainsi: le multi-tenant optimise l’échelle, le single-tenant maximise l’isolement, et le cloud privé sert surtout les contextes où contrôle et personnalisation priment sur l’optimisation de masse.
| Modèle | Ce que cela veut dire | Atout principal | Limite principale | Quand je le recommande |
|---|---|---|---|---|
| Multi-tenant | Plusieurs clients partagent la même application, avec isolation logique | Coûts maîtrisés, mises à jour rapides, bonne scalabilité | Personnalisation et isolement plus complexes | La plupart des SaaS B2B, surtout au démarrage |
| Single-tenant | Chaque client dispose de son instance dédiée | Isolation forte, contrôle fin, conformité facilitée | Coût supérieur, exploitation plus lourde | Clients sensibles, grands comptes, exigences contractuelles fortes |
| Cloud privé | Environnement dédié, souvent opéré par un tiers | Contrôle et prévisibilité | Moins d’élasticité économique qu’un modèle mutualisé | Charges stables, contraintes fortes de gouvernance |
| Hybride | Une partie du service est mutualisée, une autre dédiée | Souplesse de conception | Architecture plus difficile à maintenir | Cas où la donnée ou certains flux exigent un traitement spécifique |
Dans la vraie vie, le multi-tenant est souvent le meilleur point de départ, mais il faut accepter qu’il oblige à une discipline technique plus forte sur l’isolation des données, les quotas et la supervision. À l’inverse, le single-tenant peut rassurer, mais il devient vite coûteux si on le généralise sans raison. Cette lecture par usage prépare bien le choix du prestataire, qui reste l’étape la plus délicate.
Les critères concrets pour comparer les offres
Quand je compare des fournisseurs, je ne commence jamais par le design du site ou la liste des fonctionnalités. Je regarde d’abord des critères mesurables, parce que ce sont eux qui déterminent la qualité réelle du service après la signature.
| Critère | Ce que je demande | Signal d’alerte |
|---|---|---|
| Disponibilité | SLA, exclusions, pénalités, fenêtres de maintenance | Promesse de disponibilité sans détail contractuel |
| Réversibilité | Export des données, formats, délais, assistance à la sortie | Export manuel ou incomplet uniquement |
| Localisation | Région d’hébergement, sous-traitants, transferts hors UE | Réponse floue sur les emplacements réels |
| Support | Délais de prise en charge, canaux, niveau d’escalade | Support uniquement “best effort” |
| Surveillance | Logs, métriques, alertes, historisation | Impossible d’accéder aux journaux d’exploitation |
| Sauvegardes | Fréquence, rétention, tests de restauration | Sauvegardes non testées ou non documentées |
Je regarde aussi la lisibilité du contrat. Un fournisseur solide explique clairement ce qu’il héberge, ce qu’il sous-traite, ce qu’il monitorise et ce qu’il garantit. S’il faut interpréter chaque phrase pour comprendre où se situent les responsabilités, je considère cela comme un risque. C’est souvent à ce stade qu’on distingue une simple offre commerciale d’un vrai service d’infrastructure.
Sur les coûts, je reste prudent mais concret: un petit socle cloud peut démarrer à quelques dizaines d’euros par mois, mais dès qu’on ajoute redondance, sauvegardes sérieuses, supervision, logs conservés et support réactif, on passe vite à quelques centaines d’euros mensuels, voire davantage. Le prix n’est pas le bon indicateur à isoler; il faut le lire avec le niveau de service attendu. Cette logique devient encore plus claire quand on déroule le déploiement lui-même.
Le déploiement qui évite les mauvaises surprises
La mise en production d’un service SaaS échoue rarement sur une seule erreur spectaculaire. Elle échoue plutôt à cause d’une accumulation de petits oublis: un modèle de données pas assez isolé, des sauvegardes non testées, une supervision trop pauvre ou une réversibilité pensée trop tard.
- Je définis d’abord les frontières de chaque tenant, les règles d’accès et la sensibilité des données.
- Je mets ensuite en place l’authentification forte, la gestion des rôles et la journalisation des actions sensibles.
- J’automatise le provisionnement, les migrations et les déploiements pour éviter les opérations manuelles risquées.
- Je vérifie la supervision: métriques applicatives, alertes utiles, traces et tableaux de bord lisibles.
- Je teste la restauration réelle, pas seulement la sauvegarde, avec un exercice de reprise mesuré sur le temps et l’intégrité.
- Je lance enfin un pilote limité avant d’ouvrir le service à l’ensemble des clients.
Dans cette phase, j’aime bien valider deux choses que beaucoup de projets repoussent: le comportement sous charge et la sortie de crise. Un bon service n’est pas seulement capable d’encaisser un pic; il doit aussi pouvoir être restauré et, si nécessaire, migré ailleurs sans dépendre d’un artisanat interne impossible à reproduire. Cela paraît basique, mais c’est précisément là que les mauvaises surprises coûtent le plus cher.
Ce que je vérifierais avant de signer
Si je devais résumer ma grille de lecture en trois points, je regarderais d’abord l’isolement réel des données, ensuite la capacité à restaurer rapidement le service après incident, puis la possibilité de repartir avec ses informations dans un format exploitable. Ce triptyque dit beaucoup plus sur la qualité d’une offre que la liste des fonctionnalités affichées en vitrine.
- Isolement des données, des comptes et des environnements de test.
- Preuves de sauvegarde et de restauration, avec fréquence et résultat documentés.
- Transparence sur les sous-traitants, les régions cloud et les flux sortants.
- Réversibilité contractuelle, avec export clair et assistance à la migration.
- Support joignable et mesuré, surtout pour les incidents critiques.
Le meilleur réflexe, au fond, consiste à traiter la plateforme comme un actif stratégique et non comme une simple dépense informatique. Quand l’architecture, la sécurité et la réversibilité sont chiffrées dès le départ, l’hébergement SaaS cesse d’être une promesse floue et devient un socle de production réellement maîtrisable.