
Une défense efficace contre les rançongiciels ne se résume pas à empiler des licences. Ce qui compte vraiment, c’est l’enchaînement complet: empêcher l’entrée, détecter vite, contenir la propagation et restaurer sans réintroduire le problème. En 2026, les attaques combinent souvent chiffrement, vol de données et pression sur les sauvegardes; c’est pour cela que les ransomware solutions doivent être pensées comme une stratégie, pas comme un achat isolé.
Les points à retenir pour construire une défense qui tient sous pression
- Une bonne protection anti-rançongiciel couvre quatre couches: prévention, détection, confinement et restauration.
- Les sauvegardes immuables, la MFA sur les comptes sensibles et la réduction des privilèges ont un impact direct sur la survie d’une entreprise après incident.
- Un EDR ou un XDR aide à repérer et contenir, mais ne remplace jamais des sauvegardes testées ni une procédure de crise.
- La remédiation commence par l’isolement et la remise à zéro des accès, pas par un redémarrage précipité.
- En France, si des données personnelles sont touchées, la question CNIL se pose très vite, souvent dans un délai de 72 heures.
Ce que recouvrent vraiment les protections anti-rançongiciel
Je commence toujours par séparer la promesse marketing de la mécanique réelle. Une bonne protection anti-rançongiciel ne fait pas qu’alerter; elle réduit la surface d’attaque, limite les droits, protège les sauvegardes et prépare la reprise. Si l’un de ces étages manque, le reste devient beaucoup moins fiable.
| Couche | Ce qu’elle apporte | Ce qu’elle ne règle pas |
|---|---|---|
| Prévention | Rend l’intrusion initiale plus difficile grâce au durcissement, aux correctifs et à l’authentification forte. | Ne garantit pas qu’un compte ne sera jamais compromis. |
| Détection | Repère des comportements suspects plus tôt, par exemple un chiffrement massif ou des mouvements latéraux. | Ne restaure rien à elle seule. |
| Confinement | Freine la propagation en limitant les accès, les segments réseau et les privilèges. | Ne compense pas des identités mal gérées. |
| Restauration | Permet de redémarrer depuis une base saine, idéalement hors ligne ou immuable. | Ne sert à rien si les sauvegardes ont été exposées ou si la procédure n’a jamais été testée. |
| Conformité et preuve | Aide à documenter l’incident, la chronologie et les décisions prises. | Ne remplace pas la réponse technique. |
Selon l’ENISA, son panorama 2025 a encore passé au crible 4 875 incidents sur douze mois, ce qui confirme que le rançongiciel reste une menace structurante, pas un cas d’école. Une fois cette carte mentale en place, on peut regarder les mesures qui réduisent vraiment la probabilité d’un incident.
Les mesures qui réduisent le plus le risque
Si je dois hiérarchiser, je mets en tête les mesures qui coupent la chaîne d’attaque la plus courante: identifiants compromis, vulnérabilités exposées, droits excessifs et sauvegardes accessibles depuis le même réseau. Les outils comptent, mais l’ordre de priorité compte davantage.
| Priorité | Action concrète | Pourquoi elle change la donne |
|---|---|---|
| Sauvegardes | Appliquer une logique 3-2-1-1-0: trois copies, deux supports, une copie hors ligne ou immuable, et des tests de restauration sans erreur. | Sans restauration fiable, l’entreprise subit l’attaque au lieu de la contenir. |
| Identités | Imposer une MFA résistante au phishing sur les comptes sensibles, séparer les comptes admin et limiter les privilèges. | La majorité des chaînes d’attaque deviennent beaucoup plus difficiles à automatiser. |
| Correctifs | Traiter en priorité les systèmes exposés à Internet, les VPN, les passerelles et les serveurs critiques. | Les attaquants cherchent souvent l’entrée la plus visible et la plus rentable. |
| Segmentation | Isoler les serveurs sensibles, les sauvegardes, l’administration et les postes bureautiques. | On limite le mouvement latéral et l’extension du chiffrement. |
| Messagerie et utilisateurs | Renforcer le filtrage, bloquer les macros par défaut et cibler la sensibilisation sur les métiers les plus exposés. | Le phishing reste un point d’entrée très rentable pour l’attaquant. |
L’ANSSI insiste sur un point que je juge non négociable: l’infrastructure de sauvegarde doit être séparée de la production, sinon elle finit par être visée elle aussi. C’est précisément là que la discipline opérationnelle fait la différence, bien plus qu’un slogan de sécurité ou qu’un tableau de bord rassurant.
Le piège classique, c’est de croire qu’un seul levier suffit. En pratique, la défense tient quand plusieurs protections se renforcent mutuellement, et quand chaque exception est vraiment justifiée. C’est cette combinaison qui prépare aussi la reprise, ce qui nous amène à la remédiation elle-même.
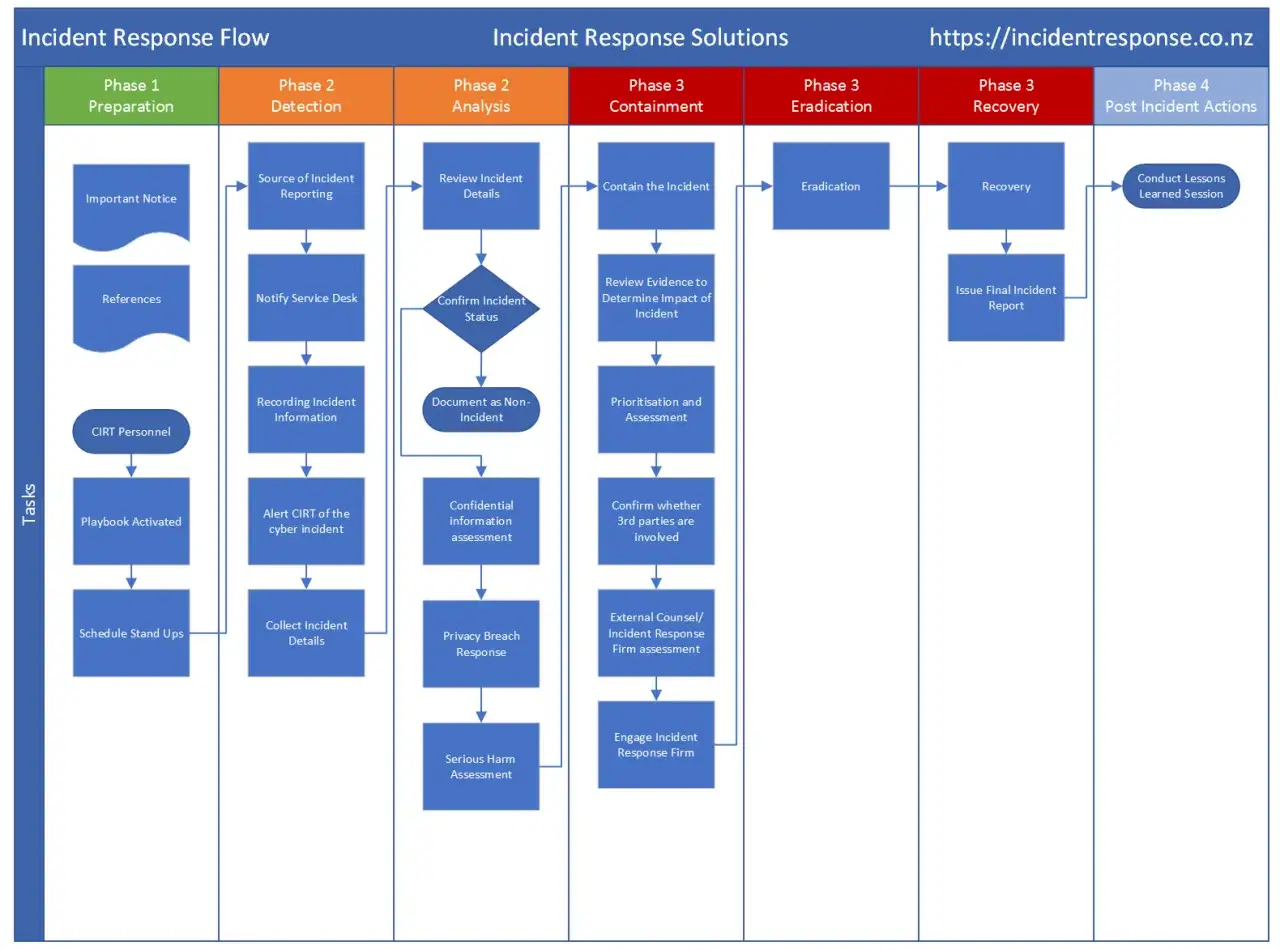
Préparer une remédiation qui tient quand tout s’emballe
Le jour où l’attaque est confirmée, la question n’est plus de savoir si l’outil est “bon”, mais si l’organisation sait exécuter les bons gestes dans le bon ordre. Je préfère un plan simple, répétable et documenté à une procédure brillante que personne n’ose suivre en crise.
- Isoler immédiatement le périmètre touché. Coupez les accès réseau inutiles, les partages, les VPN concernés et les liaisons qui permettent au rançongiciel de s’étendre.
- Bloquer les identités compromises. Désactivez les comptes suspects, révoquez les sessions actives et remettez à zéro les secrets sensibles: mots de passe, clés API, jetons et accès administratifs.
- Préserver les éléments utiles à l’analyse. Conservez les journaux, les horodatages, la note de rançon, les indices réseau et, si possible, l’état des machines les plus critiques avant toute manipulation agressive.
- Valider la méthode de reprise. Restaurer n’est pas recopier des fichiers; il faut repartir d’un environnement sain, réinstaller ou reconstruire si nécessaire, puis contrôler que la source de sauvegarde n’a pas été contaminée.
- Vérifier l’absence de persistance. Avant de reconnecter un système, cherchez les portes dérobées, les tâches planifiées, les services suspects et les comptes créés pour revenir plus tard.
- Communiquer de façon structurée. La direction, l’IT, le juridique, la communication et les prestataires doivent parler avec une seule chronologie, pas avec cinq versions de l’histoire.
Le mauvais réflexe le plus coûteux consiste à restaurer trop vite dans un environnement encore compromis. C’est souvent là qu’un incident contenu devient une crise longue, avec des allers-retours de remédiation, de re-chiffrement et de perte de confiance. Une reprise propre dépend ensuite des outils et de l’architecture choisis avant l’incident.
Choisir les bons outils sans acheter la promesse marketing
Quand je compare des outils, je regarde surtout le niveau de contrôle qu’ils apportent, pas le nombre de pages de la fiche commerciale. Une pile modeste mais bien opérée bat presque toujours un empilement d’outils sous-utilisés.
| Catégorie | Apport réel | Limite si elle est mal déployée |
|---|---|---|
| EDR / XDR | Détecte des comportements suspects sur les postes et peut isoler rapidement une machine. XDR élargit la visibilité à plusieurs couches. | Ne restaure rien et ne compense pas une sauvegarde faible. |
| Sauvegarde immuable | Conserve un point de restauration difficile à modifier ou à chiffrer depuis le réseau de production. | Utile seulement si les restaurations sont testées et si l’accès d’administration est séparé. |
| MFA et PAM | Réduit l’abus d’identifiants et encadre les privilèges d’administration. PAM signifie gestion des accès à privilèges. | Perd beaucoup de valeur si les exceptions deviennent la règle. |
| Sécurité de la messagerie | Freine le phishing, les pièces jointes piégées et les liens malveillants. | Ne bloque pas à elle seule une vulnérabilité exposée sur Internet. |
| SIEM / SOAR | Centralise les journaux et automatise certains playbooks de réponse. SOAR désigne l’orchestration et l’automatisation de la réponse. | Produit surtout du bruit si les cas d’usage ne sont pas définis. |
| Gestion des vulnérabilités | Donne une vision claire des failles à traiter en priorité. | Inutile sans propriétaire, délai de correction et suivi réel. |
Je considère qu’un bon achat est celui qui réduit un vrai risque mesurable: accès initial, propagation, ou incapacité à restaurer. Tout le reste n’est que confort de reporting. À ce stade, il reste une couche que beaucoup négligent encore: la conformité et la preuve, surtout en France.
En France, la réponse doit aussi couvrir les obligations et la preuve
Dès qu’un rançongiciel touche des données personnelles, la question n’est plus seulement technique. La CNIL rappelle qu’une notification doit intervenir dans les 72 heures lorsque l’incident crée un risque pour les droits et libertés des personnes, même si les éléments disponibles sont encore partiels au moment de la déclaration.
- Qualifier l’incident : distinguer une indisponibilité pure d’une violation de données avec risque de confidentialité, d’intégrité ou de disponibilité.
- Documenter la chronologie : heure de détection, périmètre touché, systèmes coupés, premières hypothèses et actions de confinement.
- Préparer la notification : rassembler les éléments utiles sans attendre d’avoir une vision parfaite, puis compléter ensuite si nécessaire.
- Prévoir l’information des personnes concernées : si le niveau de risque le justifie, la communication doit être claire, sobre et utile.
- Garder les traces : journaux, copies de preuve, décisions de crise et mesures correctives doivent être conservés avec rigueur.
Je conseille aussi de désigner avant la crise qui décide quoi: DSI, RSSI, juridique, direction, communication, prestataire de réponse à incident. Quand ces rôles sont flous, la panne technique se transforme vite en désordre organisationnel. Une organisation qui sait déjà quoi notifier et quoi documenter récupère plus vite la confiance en plus des systèmes.
Les signaux qui me disent qu’une stratégie est vraiment prête
Quand j’évalue une posture anti-rançongiciel, je regarde d’abord ces indices très concrets.
- Les sauvegardes sont restaurées régulièrement dans un environnement isolé, pas seulement “présentes” dans un coffre.
- Les comptes administratifs sont séparés des comptes de travail et protégés par une MFA robuste.
- Les systèmes exposés à Internet sont inventoriés, suivis et traités avec un délai de correction clair.
- Le plan de réponse à incident a déjà été exercé avec des scénarios réalistes, même courts.
- Les accès prestataires, les VPN et les droits temporaires sont gouvernés au lieu d’être tolérés par défaut.
- Les journaux utiles sont conservés assez longtemps pour reconstruire une chronologie exploitable.
Si ces points sont vérifiés avant l’incident, la reprise cesse d’être une improvisation. C’est, à mes yeux, la vraie mesure d’efficacité d’une stratégie anti-rançongiciel: empêcher au maximum, contenir rapidement, puis restaurer proprement sans négocier avec le chaos.