Un data center Microsoft n’est pas seulement un bâtiment rempli de serveurs. C’est une infrastructure complète, où l’alimentation électrique, le refroidissement, le réseau et la sécurité sont conçus pour servir le cloud à grande échelle sans perdre de vue la disponibilité, la résidence des données et les contraintes opérationnelles. Dans cet article, je détaille la manière dont ces centres fonctionnent, pourquoi les régions Azure comptent autant et ce que cela change concrètement pour une entreprise en France.
Les points essentiels à garder en tête avant de comparer les régions Azure
- Un centre de données Microsoft s’inscrit dans une région Azure, elle-même rattachée à une géographie qui sert de frontière de résidence des données.
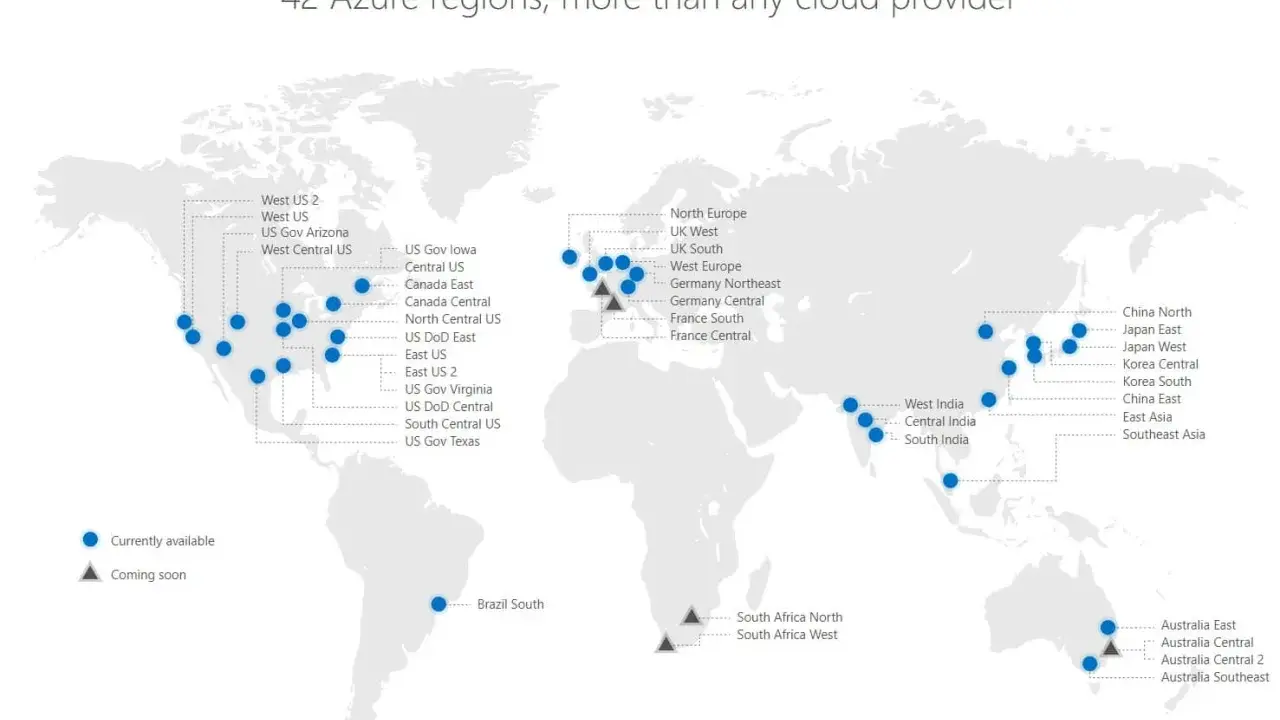
- Microsoft annonce aujourd’hui plus de 80 régions Azure, plus de 500 centres de données, 34 pays hébergeant des datacenters et plus de 800 000 kilomètres de fibre.
- Les zones de disponibilité servent à encaisser une panne locale sans faire tomber l’ensemble du service.
- La disponibilité réelle dépend toujours de la région choisie, mais aussi du service Azure concerné.
- En France, le vrai sujet n’est pas seulement la latence: c’est aussi la conformité, la redondance et la disponibilité des produits dans la bonne région.
- La durabilité n’est pas un thème annexe; elle influence déjà le refroidissement, la densité de calcul et le coût d’exploitation.
Ce que recouvre un centre de données Microsoft
Je préfère partir d’une idée simple: un centre de données Microsoft est une brique physique du cloud, mais il n’est jamais isolé. Il s’inscrit dans une région Azure, elle-même rattachée à une géographie qui sert de frontière de résidence des données. La documentation Azure rappelle qu’une région regroupe un ou plusieurs centres de données reliés par un réseau haut débit, tolérant aux pannes et à faible latence.
À l’échelle mondiale, Microsoft annonce plus de 80 régions Azure, plus de 500 centres de données, 34 pays hébergeant des datacenters et plus de 800 000 kilomètres de fibre. Ce n’est pas un simple chiffre marketing: cette densité explique la proximité des services, la redondance possible et la capacité à absorber des charges IA bien plus lourdes qu’avant.
| Bloc | Rôle | Pourquoi c’est important |
|---|---|---|
| Calcul | Héberge les machines virtuelles, conteneurs et services managés | Détermine la puissance disponible et la capacité à monter en charge |
| Stockage | Conserve les données, sauvegardes et journaux | Influe sur la résilience, la rétention et le coût global |
| Réseau | Relie racks, zones, régions et utilisateurs | Conditionne la latence, la continuité de service et l’accès aux applications |
| Refroidissement et énergie | Maintient les équipements dans une plage de fonctionnement stable | Fait la différence entre une plateforme robuste et une plateforme sous tension permanente |
| Sécurité physique et logique | Protège les bâtiments, les équipements et les flux de données | Réduit le risque d’intrusion, d’erreur humaine et d’interruption involontaire |

Comment l’infrastructure est organisée
La structure d’un centre de données cloud repose sur plusieurs couches qui se répondent. D’un côté, il y a les bâtiments, les zones techniques, l’alimentation secourue et le refroidissement. De l’autre, il y a le maillage réseau, les dispositifs de sécurité et l’automatisation qui permettent d’exploiter des milliers de serveurs comme un ensemble cohérent.
La logique Microsoft est simple à résumer: la région est l’unité de service, la zone de disponibilité est l’unité de protection, et le réseau est le liant opérationnel. Dans une région, les équipements sont répartis entre plusieurs zones physiques séparées, avec des infrastructures indépendantes de puissance, de refroidissement et de connectivité.
| Élément | Fonction | Ce que cela change pour l’utilisateur |
|---|---|---|
| Région | Regroupe un ou plusieurs centres de données | Définit l’emplacement logique des services et la résidence des données |
| Géographie | Encadre les exigences de conformité et de résidence | Permet d’aligner architecture cloud et contraintes réglementaires |
| Zone de disponibilité | Sépare physiquement les ressources à l’intérieur d’une région | Améliore la tolérance aux pannes locales |
| Réseau mondial | Relie datacenters, points de présence et clients | Réduit la latence et améliore le routage vers les services |
Pour un lecteur français, ce point mérite une attention particulière. La géographie Azure France comprend notamment France Central et France Sud, mais la bonne région ne se choisit pas au feeling: il faut vérifier la disponibilité du service voulu, les exigences de conformité et le niveau de redondance réellement possible. C’est ce passage du “où est le datacenter” au “comment le service est distribué” qui évite beaucoup d’erreurs.
Cette organisation n’a pourtant de valeur que si elle est exploitée proprement au quotidien, ce qui nous amène au cœur du sujet opérationnel.
Ce qui se passe derrière l’exploitation quotidienne
Ce que l’on sous-estime souvent, c’est la part de routine. Un datacenter n’est pas un décor technique: il faut le surveiller, le maintenir, le faire évoluer et, parfois, le retirer proprement du service sans interrompre les workloads. Je vois quatre priorités dans l’exploitation réelle.
- La supervision en continu, pour suivre l’état des serveurs, du stockage, du réseau et des ressources d’énergie.
- La planification de capacité, pour anticiper les besoins liés aux pics de charge, à l’IA ou à la croissance d’un service.
- La maintenance par vagues, afin de mettre à jour ou remplacer du matériel sans provoquer de panne générale.
- La gestion du cycle de vie, qui inclut la réparation, le réemploi et le recyclage du matériel retiré.
Cette mécanique devient plus délicate avec les workloads IA. Les GPU et les serveurs haute densité génèrent plus de chaleur, consomment davantage et imposent des choix de refroidissement plus exigeants. C’est pour cela que Microsoft investit dans des approches de refroidissement liquide et de gestion thermique plus avancées: l’enjeu n’est pas seulement de “garder les machines au frais”, mais de maintenir la densité tout en gardant la stabilité.
À mes yeux, c’est là que l’exploitation cloud se distingue d’un datacenter classique: à grande échelle, chaque détail compte, y compris ce qu’on ne voit pas depuis l’interface Azure. Et dès qu’on parle de continuité, la question suivante devient inévitable: comment résister à une panne locale ou régionale ?
Résilience, sécurité et continuité de service
Les zones de disponibilité sont le mécanisme le plus visible, mais pas le seul. Elles reposent sur des groupes physiques séparés à l’intérieur d’une région, avec des infrastructures indépendantes. L’idée est simple: si une zone tombe, les autres continuent à servir la charge. Dans les régions qui le supportent, c’est l’un des moyens les plus efficaces de limiter l’impact d’un incident local.
Il faut cependant éviter un malentendu fréquent: la haute disponibilité ne remplace ni la sauvegarde ni le plan de reprise. Elle réduit l’exposition à certaines pannes, mais ne couvre pas tout. Une bonne architecture cloud combine souvent plusieurs niveaux de protection.
| Mécanisme | Ce qu’il protège | Sa limite |
|---|---|---|
| Zone de disponibilité | Panne locale d’infrastructure | Ne remplace pas la stratégie de sauvegarde |
| Réplication interrégions | Incident plus large touchant une région entière | Peut augmenter la latence et les coûts |
| Sauvegarde externalisée | Erreur humaine, corruption, ransomware | Demande une politique de restauration testée |
| Sécurité multicouche | Accès physique et logique | Ne dispense jamais d’une bonne gouvernance client |
Sur la sécurité, Microsoft insiste sur une approche multicouche qui couvre les datacenters, l’infrastructure et les opérations. L’entreprise s’appuie aussi sur plus de 3 500 experts cybersécurité à l’échelle mondiale. Ce volume de compétences ne garantit pas l’absence d’incident, mais il montre une réalité simple: à cette échelle, la sécurité est un métier industriel, pas un contrôle ponctuel.
Je retiens ici une règle pratique: plus une charge est critique, plus il faut traiter le cloud comme une architecture de résilience, pas comme un simple hébergement. C’est un bon point de transition vers un sujet qu’on laisse trop souvent en second plan, alors qu’il change la conception même des sites: l’énergie et l’eau.
Énergie, eau et pression environnementale
La durabilité n’est plus un sujet périphérique. Elle influence le type de refroidissement, la densité de calcul, les matériaux, le cycle de vie des équipements et, au final, le coût opérationnel. Microsoft vise un objectif de carbone négatif, eau positive et zéro déchet d’ici 2030, avec aussi une ambition de meilleure efficacité énergétique et hydrique sur ses datacenters.
Concrètement, cela pousse vers plusieurs directions: des systèmes de refroidissement plus sobres, de nouvelles architectures thermiques, une meilleure réutilisation des équipements et, dans certains cas, la valorisation de la chaleur produite. Ce n’est pas de la communication plaquée sur la technique; c’est une réponse à la densité croissante des charges cloud et IA.
- Le refroidissement devient une variable de performance, parce qu’il conditionne la densité des racks et la stabilité des serveurs.
- L’usage de l’eau doit être maîtrisé, ce qui explique l’attention portée aux gains d’efficacité et aux systèmes fermés ou moins consommateurs.
- Le matériel doit être pensé pour durer ou être réemployé, afin de réduire les déchets et les remplacements trop fréquents.
Je trouve ce point central, car il corrige une idée encore trop répandue: un datacenter n’est pas “vert” par accident, il le devient par conception. Et plus les charges augmentent, plus cette discipline technique compte dans la vraie vie.
Ce que cela change pour une entreprise en France
Pour une entreprise française, le sujet n’est pas seulement technique. Il est aussi réglementaire, économique et géographique. La première question que je pose toujours est la suivante: où doivent vivre les données, et pourquoi ? Ensuite seulement viennent la latence, la haute disponibilité et le budget d’exploitation.
Dans le cas d’Azure, la géographie France et ses régions doivent être évaluées service par service. Ce point est capital, parce que la proximité géographique ne suffit pas si le service visé n’est pas proposé dans la bonne région. À l’inverse, un service disponible dans la région souhaitée peut encore imposer des compromis sur la redondance ou sur l’architecture multi-zone.
| Critère | Ce qu’il faut vérifier | Impact concret |
|---|---|---|
| Résidence des données | La géographie et la région Azure réellement utilisées | Conformité, souveraineté, localisation juridique |
| Disponibilité des services | La liste des produits Azure disponibles dans la région | Possibilité réelle de déployer l’architecture prévue |
| Résilience | Support des zones de disponibilité et options de reprise | Capacité à encaisser une panne sans arrêt majeur |
| Latence | Distance entre utilisateurs, applications et région | Expérience utilisateur et performance applicative |
| Coût | Réplication, stockage, trafic inter-régions, sauvegardes | Budget d’exploitation sur la durée |
En pratique, je conseille toujours de raisonner en trois temps: choisir la bonne géographie, vérifier les services disponibles, puis dessiner la redondance autour des zones et du plan de reprise. C’est souvent là que se joue la différence entre un projet cloud solide et une architecture séduisante sur le papier mais fragile en production.
Ce qu’il faut vérifier avant de s’engager sur Azure
Si je devais résumer l’ensemble en une phrase, je dirais qu’un datacenter cloud se juge moins à son existence qu’à la qualité du système qui l’entoure: région, réseau, zones, opérations, sécurité et énergie. C’est ce maillage qui fait la valeur réelle du service, bien plus que le simple nombre de serveurs.
En 2026, l’enjeu n’est plus seulement de “mettre des machines en ligne”. Il faut faire tenir ensemble l’IA, la continuité de service, la conformité et les objectifs environnementaux, sans sous-estimer les compromis de coût et de disponibilité. Avant de décider, je vérifierais donc toujours la région, les zones de disponibilité, la liste exacte des services disponibles et la stratégie de reprise après incident. C’est la manière la plus fiable d’éviter les mauvaises surprises, surtout pour une application critique ou soumise à des contraintes de résidence des données.